
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄

部署具有大型语言模型 (LLM) 的应用程序面临两个挑战。首先,虽然法学硕士正在彻底改变许多领域,但培训和部署这些模型的复杂性限制了资源丰富的行业实验室之外的个人的访问能力。例如,一家旨在开发基于语言的虚拟助手的小型初创公司可能在获取有效部署大型语言模型所需的资源和专业知识方面面临困难。其次,某些开源模型仅限于研究目的,不能用于商业应用。此限制可能会给希望利用开源模型构建需要商业使用权的面向客户的应用程序的企业带来挑战。这引发了一波围绕开源模型的活动,
MosaicML 为应对这些挑战,推出了新的基础模型系列 MPT(MosaicML Pretrained Transformer)。该系列旨在规避现有模型的局限性,提供商业上可行的开源模型,该模型等于并常常超越 LLaMA-7B 的功能。
使用开源基础模型构建的示例应用程序
例如,社交媒体平台可以利用开源基础模型来开发特定领域的法学硕士,以增强内容审核、检测和减少有害或误导性信息,并营造更安全的在线环境。通过利用开源语言模型 (LLM) 提供的可访问性和定制选项,该平台可以整合定制的解决方案来解决特定的内容挑战,并受益于开源社区促进的透明度和协作开发。这不仅确保了成本效益,还促进了持续的学习过程,并使平台能够主动解决新出现的问题,最终改善用户体验和社区福祉。

例如,社交媒体公司可以微调基础模型,以准确检测和消除仇恨言论,从而培育一个更安全、更具包容性的在线社区。
Mosaic的开源模式是什么
MosaicML 的 MPT-7B 是一种基于 Transformer 的语言模型,在数量惊人的 1 万亿个文本和代码上从头开始训练,现已开源并可用于商业用途。MPT-7B 不仅与 LLaMA-7B 等模型的质量相匹配,而且还解决了其他开源 LLM 的现有限制。MPT-7B 的训练过程在 MosaicML 平台上在 9.5 天的令人印象深刻的时间内完成,没有任何人工干预。利用其先进的培训基础设施,MPT-7B 的培训成本约为 200,000 美元,在效率和可承受性方面代表了非凡的壮举。

使用人工智能创建。
这就是 MPT 在竞争中脱颖而出的原因:
- 商业许可
与 LLaMA 不同,MPT 获得商业用途许可,这使其成为个人和企业的可行选择。例如,一家希望增强其客户支持系统的零售公司可以利用 MPT 构建专门针对其自己的客户服务数据进行训练的特定领域模型。这种利用 MPT 商业许可构建的定制模型使零售公司能够根据其独特的产品和服务量身定制个性化且高效的客户支持。
- 广泛的训练数据
MPT模型在海量数据上进行训练,1万亿代币的规模可与LLaMA相媲美。这远远超过了其他流行开源模型的训练数据大小,例如 Pythia、OpenLLaMA 和 StableLM。
- 处理长输入
得益于 ALiBi,MPT 模型能够处理极长的输入,最多可容纳 84,000 个令牌。这远远超过了其他开源模型的输入长度容量,其他开源模型的输入长度通常为 2,000 到 4,000 个令牌。在法律领域,MPT 的这种扩展输入能力被证明是无价的。例如,律师事务所可以利用 MPT 处理长输入的能力来分析冗长的法律合同或复杂的法律文档,而无需进行繁琐的手动分割。这使得法律专业人士能够获得全面的见解,并更有效、更准确地从大量法律文本中提取关键信息。
- 提高效率
MPT 模型针对训练和推理进行了优化,利用 FlashAttention 和 FasterTransformer 提供闪电般的性能。这种效率使用户能够释放 MPT 模型的全部潜力。
- 开源培训代码
MosaicML 致力于培育协作社区。作为这一使命的一部分,我们提供高效、透明的开源培训代码,促进法学硕士领域的进步。
除了基本 MPT 模型之外,Mosaic 还发布了其他三个经过微调的变体,以展示这一变革模型的广泛可能性。我们将在下一节中对此进行描述。
MPT-7B的新领域:适合各种应用的多种变体
MPT-7B 的价值并不局限于其独立功能。当这种新型变压器的底座经过扩展和微调以满足不同的应用需求时,它的真正潜力就会显现出来。
除了基本模型之外,MosaicML 还推出了三个经过微调的模型,每个模型都体现了利用 MPT-7B 基础的不同方法。
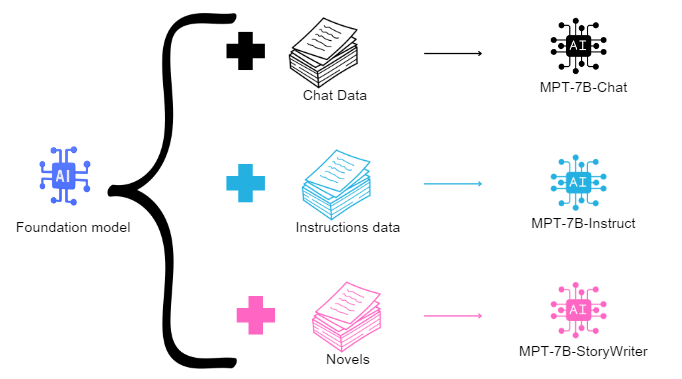
通过使用指令数据、聊天数据和小说对 MosaicML MPT 基础模型进行微调,MosaicML 成功导出了三个不同的模型:MPT-7B-Instruct、MPT-7B-Chat 和 MPT-7B-StoryWriter。
MPT-7B-Instruct
https ://huggingface.co/mosaicml/mpt-7b-instruct
该模型提出了一种利用 MPT-7B 执行简短指令的有前途的方法。这是在源自 Databricks Dolly-15k 和 Anthropic Helpful and Harmless (HH-RLHF) 数据集的数据集上进行训练的。该模型使用 960 万个令牌进行训练。这是 HuggingFace 链接:
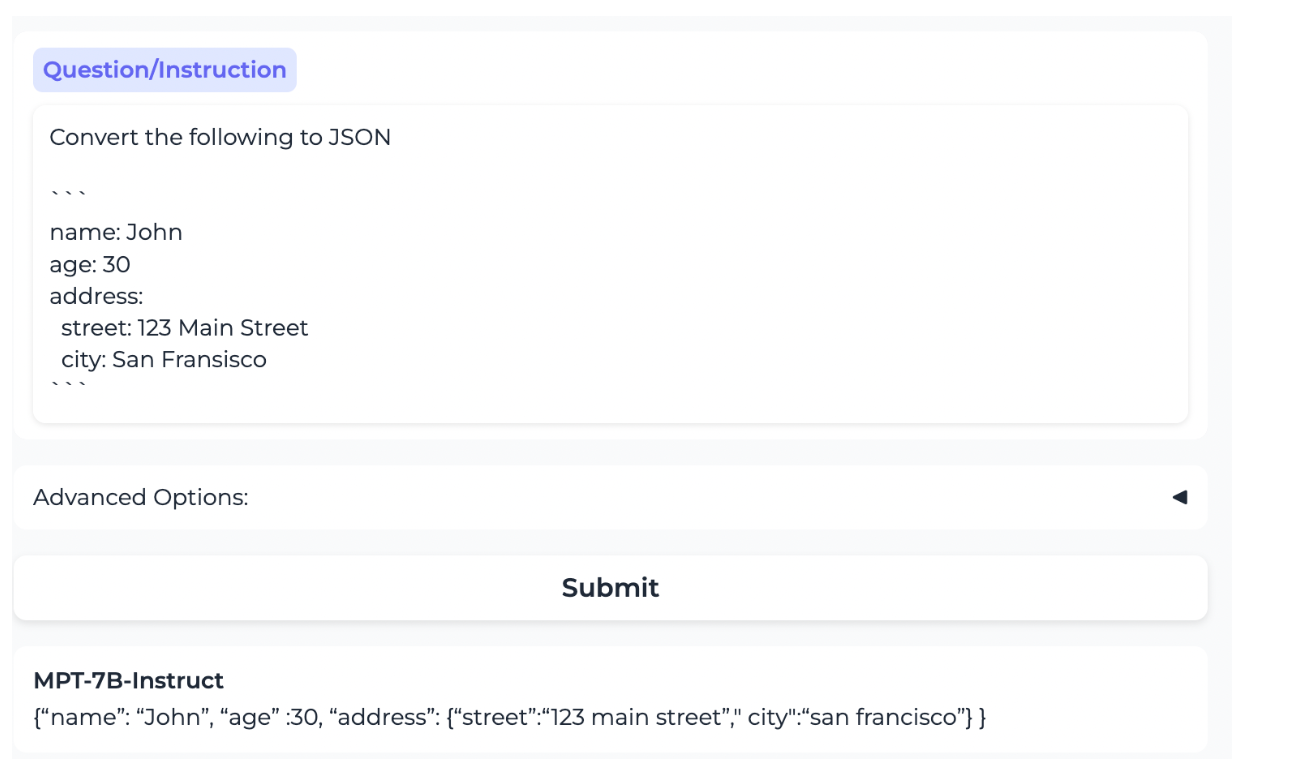
来自 Mosaic ML 论文。该模型正确地将 YAML 格式的内容转换为 JSON 格式的相同内容。
MPT-7B-Chat
MPT-7B-Chat,顾名思义,将变压器转变为聊天机器人,证明了模型在实时交互中的多功能性。该模型使用 86M 个令牌进行训练。这是 HuggingFace 链接:

来自 Mosaic ML 论文。基于MPT的微调聊天模型
MPT-7B-StoryWriter-65k+
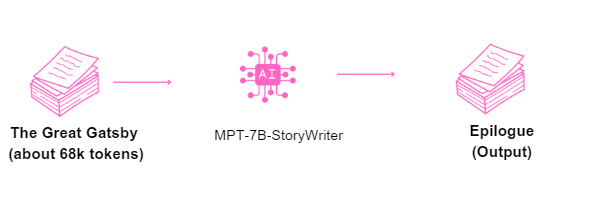
MPT-7B-StoryWriter-65k+ 可能是三者中最雄心勃勃的,它使用了高达 65k 令牌的上下文长度!这对于需要长期保留上下文的应用程序(例如讲故事、文档或大规模数据分析)特别有利。该模型使用 5B 令牌进行训练。这是 HuggingFace 链接:
65k 令牌内存有一个显着的好处。您可以在此处阅读有关此内容的更多信息。在 MosaicML 提供的示例中,他们将《了不起的盖茨比》的整个文本(大约 68k 个标记)作为模型的输入,后跟单词“Epilogue”,并允许模型从那里继续生成。
使用 AI 创建。可以记住 65k 个标记的语言模型可用于协助创意写作项目,例如写小说或剧本。通过记住之前的对话和角色互动,该模型可以帮助作家保持故事讲述和角色发展的一致性。
训练流数据:训练期间自动恢复
MosaicML 团队在训练期间利用 StreamingDataset 高效托管数据并将其从标准云对象存储流式传输到计算集群。这种方法有几个好处,包括无需在开始训练之前下载整个数据集。此外,它允许从数据集中的任何点(例如崩溃之前)无缝恢复训练,而无需从头开始快进数据加载器

来自 Mosaic ML 论文。如果作业运行时发生硬件故障,MosaicML 平台会自动检测故障,暂停作业,封锁任何损坏的节点,然后恢复作业。MPT-7B训练运行期间,他们遇到了4次这样的故障,每次都自动恢复工作
在 MosaicML 云上自定义数据训练
例如,假设您想要为制造数据创建专门的语言模型。您现在可以使用 MosaicML 的英雄聚类产品从头开始训练新模型。您所需要做的就是选择所需的模型大小和代币预算,将制造数据上传到 S3 等存储平台,然后使用 MosaicML 命令行界面 (MCLI) 开始工作。在短短几天内,您将拥有专门为生物医学文本分析量身定制的自定义语言模型。
结束语:MosaicML 展望未来
MosaicML MPT系列的推出提醒人们,人工智能的边界正在不断扩大。开源创新和商业可用性继续推动人工智能可访问性的进步。
MPT-7B 代表了人工智能之旅的重大进步,提供了强大、高质量、商业上可行的解决方案。它对 LLaMA-7B 的成功基准测试,加上处理大量输入的能力,为人工智能探索的新时代奠定了基础。
凭借开源和商业上可行的平台,我预计充满活力的研究人员、开发人员和爱好者社区将产生非凡的创新,他们都有权训练、微调和部署他们独特的 MPT 模型。
作者:斯里拉姆·帕塔萨拉蒂
- 作者:Inevitable AI
- 链接:https://www.Inevitableai.ltd/article/share94
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。