
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄
摘要
谷歌 DeepMind的Gemini是目前最先进的AI模型之一,已经超越了GPT-4。它是一个原生多模态模型,具有出色的性能和能力。
亮点
• 💎 Gemini是一种原生多模态模型,可同时处理文本、代码、图像、音频和视频。
• 💡 Gemini Ultra在多个学术基准测试中取得了优异的成绩,包括在MMLU和MMMU上超越人类专家。
• 🌍 Gemini有三种类型:Ultra、Pro和Nano,适用于不同的应用场景和设备。
• 🚀 Gemini的性能超过了GPT-4,并且谷歌DeepMind已经发布了AlphaCode 2,进一步提升了模型的能力。
• 📈 Gemini代表了人工智能领域的进步,展示了多模态和原生设计的潜力。
基于对该文章的阅读,Gemini模型的性能和多模态能力令人印象深刻。它的发展标志着人工智能领域的重要进展,为未来的研究和应用提供了新的可能性。
本文是对我们迄今为止所掌握的信息以及我所读内容的第一印象(尚未测试该模型)的快速概述。在接下来的几天里,我将更深入地了解 Gemini 可以做什么、它是如何构建的(希望如此)、它是如何工作的以及它对人工智能的未来意味着什么。
Gemini 规格、类型(Ultra、Pro、Nano)和可用性
Gemini Ultra 是实现最先进 (SOTA) 基准测试并在各个基准测试中超越 GPT-4 的版本(我们很快就会看到)。它被设计为在数据中心上运行,因此您无需将其安装在家庭计算机上。它仍在接受安全审查,将于 2024 年初在新版本的 Google Bard Advanced 上使用。
Gemini Pro 与 GPT-3.5 相当(但并不总是更好),并且针对“成本和延迟”进行了优化。如果您不需要最好的并且成本是一个限制,Pro 可能是比 Ultra 更好的选择(就像 ChatGPT 一样,GPT-3.5 是免费的,对于大多数任务来说,比每月支付 20 美元购买 GPT 更好)。 Gemini Pro 已在 170 个国家(不包括欧盟/英国)的 Bard 上以英语提供(“迄今为止最大的升级”)。Google 稍后将扩大在其他国家/地区和语言的可用性。
Gemini Nano 是针对设备的模型。谷歌尚未透露Ultra和Pro的参数数量,但我们知道Nano分为两层,Nano 1(1.8B)和Nano 2(3.25B),分别针对低内存和高内存设备。Gemini Nano 内置于谷歌 Pixel 8 Pro 中,它将成为一款全面的 AI 增强型智能手机。这就是超级Siri移动助手的开始。Gemini 还将“出现在我们的更多产品和服务中,例如搜索、广告、Chrome 和 Duet AI”,但没有具体说明其大小或时间。
它们都具有 32K 上下文窗口,明显小于最大的 Claude 2 (200K) 和 GPT-4 Turbo (128K)。很难说上下文窗口的大小是最佳的(显然取决于任务),因为,如果大小太大,模型往往会忘记很大一部分上下文知识。据报道,Gemini模型“有效地利用了它们的上下文长度”,这可能是对此类检索失败的隐含参考。
正如您所期望的,考虑到当今人工智能领域对封闭性的普遍偏好,我们对训练或微调数据集一无所知(除了数据集包含“来自网络文档、书籍和代码的数据,并包括图像、音频、和视频数据”),或模型的架构(此外,它们“构建在 Transformer 解码器之上”并且“通过架构和模型优化的改进得到增强”)。
说起来很搞笑,但我们必须等到 Meta 发布其下一个模型才能了解更多信息。开源 Llama 3(如果它在性能方面与 GPT-4 和 Gemini 进行比较)将揭示这些模型的构建方式以及它们的训练内容。
最后要说明的是,谷歌 DeepMind 还在Gemini 之上发布了AlphaCode 2 。它解决的问题比其前身 AlphaCode 多 1.7 倍,并且表现优于 85% 的参赛者。这主要与竞争性编程相关,但在这里值得一提。
Gemini Ultra 优于 GPT-4
无论是在科学层面还是商业层面,这可能都是最重要的消息。近一年来,AI 模型首次超越了 GPT-4。Gemini Ultra 在 32 个“广泛使用的学术基准”中的 30 个上实现了 SOTA。来自博客文章:
Gemini Ultra 的得分高达 90.0%,是第一个在 MMLU(大规模多任务语言理解)上超越人类专家的模型,该模型结合了数学、物理、历史、法律、医学和伦理学等 57 个科目来测试知识和解决问题的能力……Gemini Ultra 在新的 MMMU 基准测试中也取得了 59.4% 的最高分数,该基准测试由跨越不同领域、需要深思熟虑的推理的多模态任务组成。
Gemini Ultra 在 18 个基准测试中的 17 个中超过了 GPT-4,其中包括 MMLU(90% vs 86.4%,使用新型思想链方法)和新的多模态基准 MMMU(59.4% vs 56.8%)。有趣的是,Gemini 并不比 GPT-4 多多少。这表明改进这些系统有多么困难,比谷歌无力应对 OpenAI 更困难。以下是这些与其他文本和多模态基准的比较:
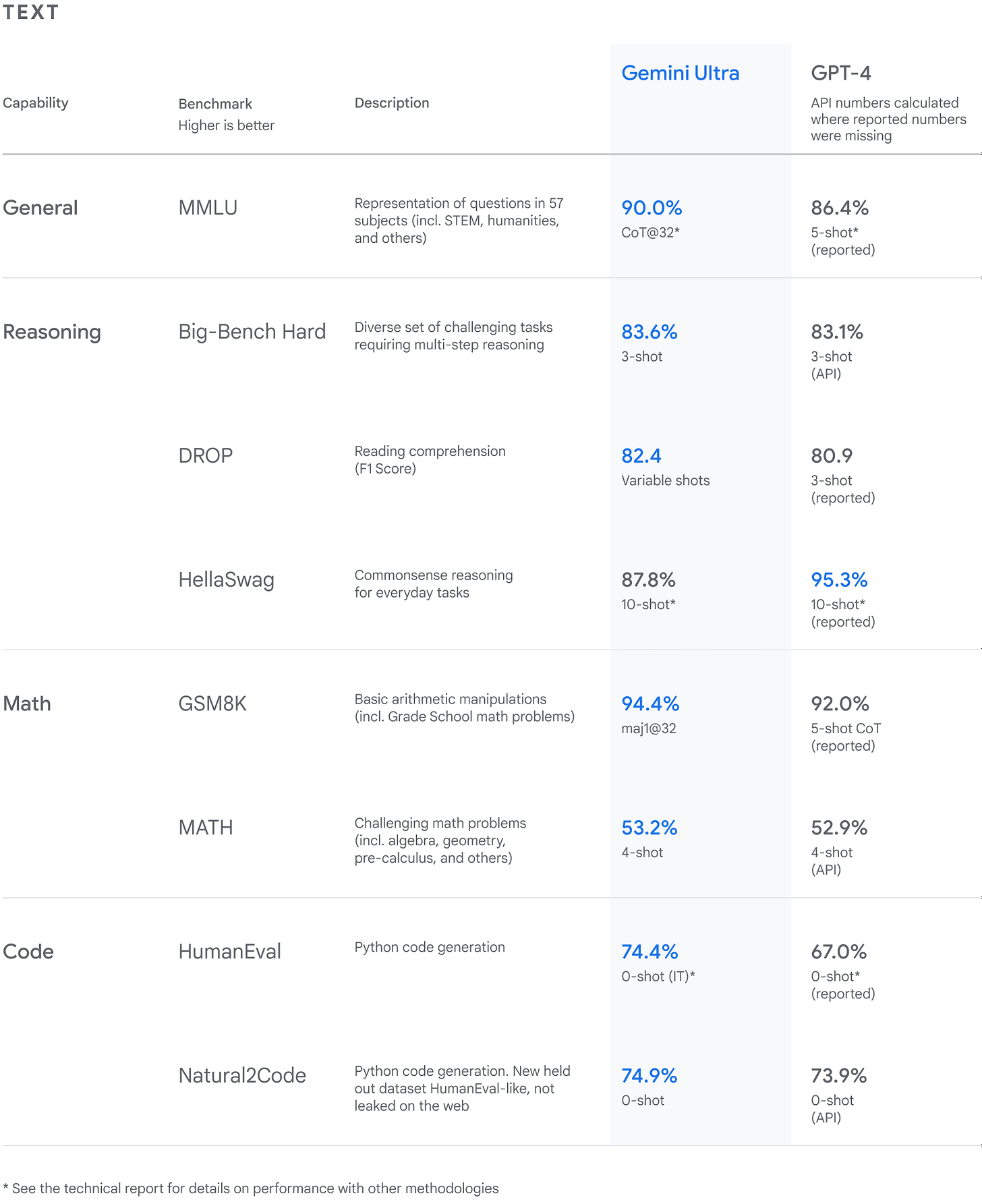
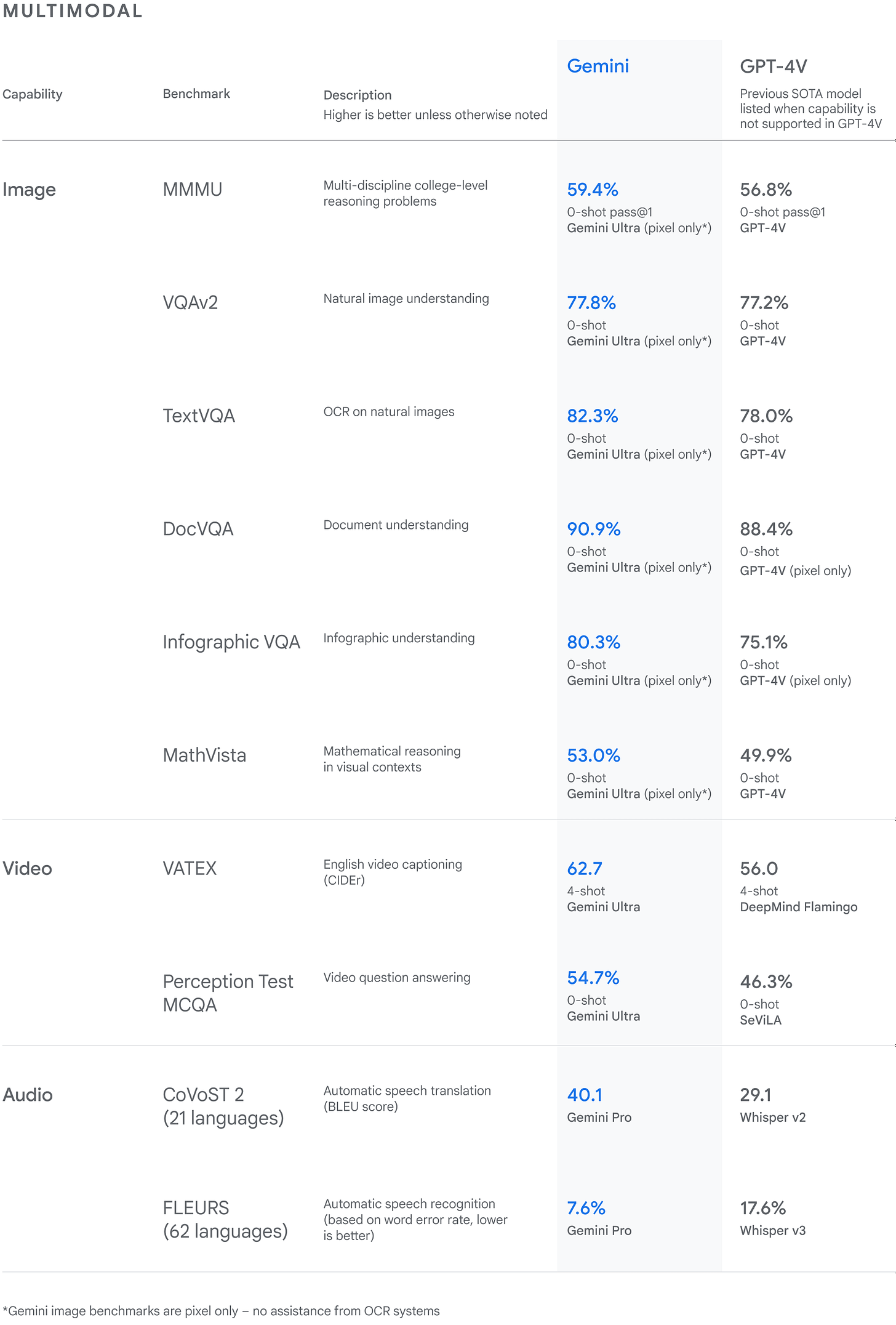
来源:谷歌 DeepMind
如果您想通过实际测试了解更多有关 Gemini 的功能(例如,推理和理解、解决数学和编码问题等),我建议您观看Google DeepMind 互动博客文章中的视频以及首席执行官 Sundar 的综合演示Pichai 发表在 X 上(两者都非常值得关注,以更好地理解上述数字的含义)。
我认为在我们能够真正测试 Gemini 的性能之前,这对于 Google 来说已经足够了。我将把技术报告结论的摘录放在这里,以防你误以为 Gemini 已经克服了现代人工智能系统的所有问题——幻觉和高级推理仍未解决:
尽管 LLM 的能力令人印象深刻,但我们应该注意到, LLM 的使用存在局限性。需要持续研究和开发 LLM 产生的“幻觉”,以确保模型输出更加可靠和可验证。尽管 LLM 在考试基准上取得了令人印象深刻的表现,但他们也很难完成需要高级推理能力的任务,例如因果理解、逻辑演绎和反事实推理。
Gemini 天生就是多模态
这里要注意的词是“天生”,但让我们首先回顾一下多模态。多模态人工智能可以处理不同的数据类型,这与仅接受文本作为输入并生成文本作为输出的语言模型形成鲜明对比。这是我文章中的简要解释:
具体来说,人工智能中的多模态是什么样的,我们可以说,在最弱的一侧,我们有视觉+语言。DALL-E 3(将文本作为输入并生成图像作为输出)和 GPT-4(将文本或图像作为输入并生成文本)是弱多模态的突出示例。最强大的一面仍未被探索,但原则上,人工智能可以获取人类拥有的每一种感觉方式(甚至更多),包括那些提供动作能力的感觉方式(例如本体感觉和机器人的平衡感)。
Gemini 模型经过训练,可以适应与各种音频和视觉输入交错的文本输入,例如自然图像、图表、屏幕截图、PDF 和视频,并且它们可以生成文本和图像输出。
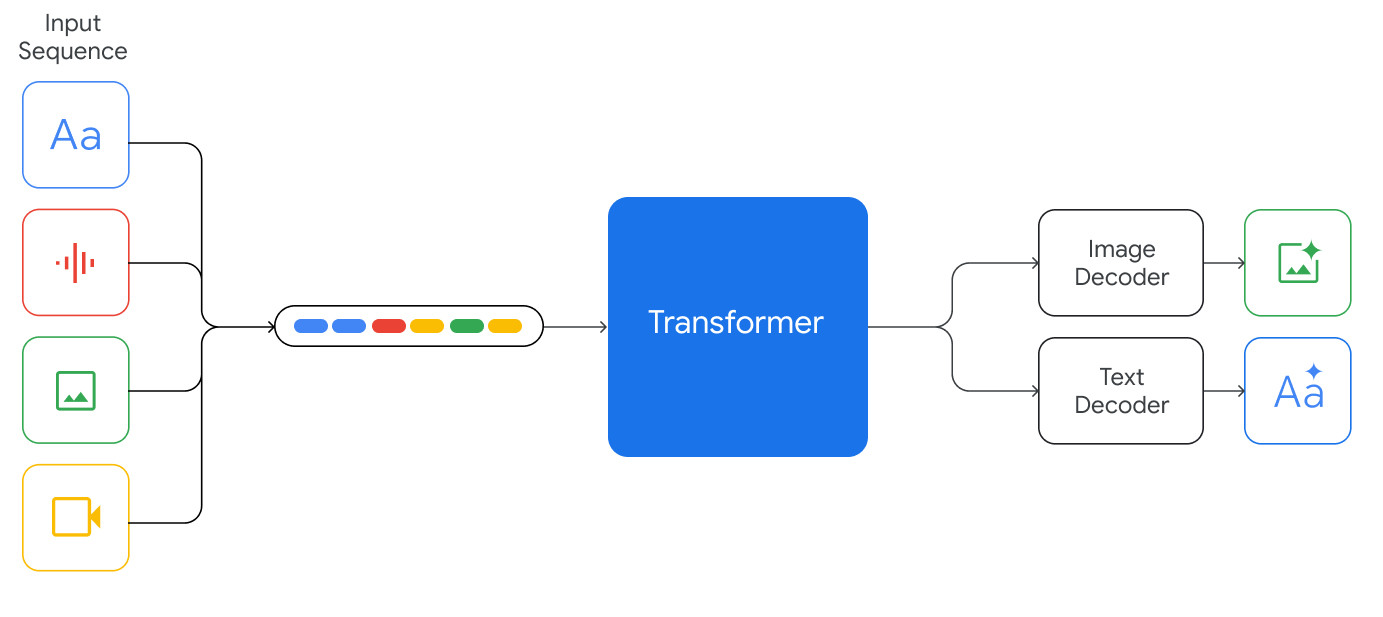
来源:谷歌 DeepMind
需要多模态才能更深入地了解世界。一些人认为,当语言模型试图通过处理文本数据中的统计相关性来预测下一个单词时,语言模型会开发出内部世界模型,但如果这是真的,那么这些模型是非常有限的。随着科学家建立可以解析更多信息模式的模型,它们的内部表征变得更加丰富——在极端情况下,它们会与我们的相匹配。
然而,构建多模态人工智能有两种不同的方法。这就是 Gemini 独特的原生多模态设计的亮点。第一种方法之前已被探索过多次,包括添加能够处理不同输入/输出的不同模块。这表面上有效,但并没有为系统提供编码更丰富的多模式世界模型的方法。以下是 Google DeepMind 首席执行官 Demis Hassabis在博客文章中对此的评论:
到目前为止,创建多模态模型的标准方法涉及针对不同模态训练单独的组件,然后将它们拼接在一起以粗略地模仿其中的一些功能。这些模型有时擅长执行某些任务,例如描述图像,但难以处理更概念性和复杂的推理。
第二种方式大概只有 Gemini 采用,需要从头开始将人工智能系统构建为多模态。与 GPT-4 不同,Gemini 从一开始就经过了预训练,然后针对多模式数据进行了微调。以下是哈萨比斯对这种新方法的看法:
我们将 Gemini 设计为原生多模态,从一开始就针对不同模式进行了预训练。然后我们使用额外的多模态数据对其进行微调,以进一步完善其有效性。这有助于 Gemini 从头开始无缝地理解和推理各种输入,远远优于现有的多模式模型 - 而且其功能几乎在每个领域都是最先进的。
第二种多模态方法更像是人脑如何从与多模态世界的多感官接触中学习。如果有一种方法可以实现真正的通用智能(或者至少是人类水平的智能,这与通用智能不同),那就是通过这种默认的多模态。该视频演示清楚地展示了本机多模态所赋予的令人印象深刻的功能。
接下来的步骤是规划和机器人技术:
人工智能公司开发出能够看、听、说话、创造、移动、计划并利用外部信息和知识做出合理决策以实现目标的系统只是时间问题。Google DeepMind 的 Gemini 和 OpenAI 大概是朝这个方向迈出的一步(特别是通过学习和搜索解决规划问题)。
Google DeepMind 首席执行官 Demis Hassabis向 Platformer 的 Casey Newton 证实,他们“正在认真思考……基于代理的系统和规划系统”。在与 Wired 的 Will Knight 的对话中,他重申了将 Gemini 与机器人技术相结合的类似愿景:“要成为真正的多模式,你需要包括触摸和触觉反馈……应用这些基础型模型有很多希望到机器人技术,我们正在大力探索。”
请随意将这些评论视为 Google DeepMind 计划在 2024 年做什么的高级路线图。
对现有信息的分析
谷歌兑现了其隐含的承诺:Gemini 在几乎所有基准测试中都优于 GPT-4。就其本身而言,它可能值得花费数百万美元。这是四年来第一次有人超越 OpenAI。无论如何,在我们过度炒作 Gemini 之前,我们应该等待 Google 在 2024 年初宣布 Bard Advanced,将其与 GPT-4 Turbo 进行测试,然后决定哪一个更好。也许现在要问的正确问题是:由于 Gemini 的(未知)架构,随着时间的推移,Gemini 能否比 GPT 更快地改进?但是,当然,我们不知道答案。
值得注意的是,如果你仔细观察基准评估中报告的数字,Gemini 最多只击败 GPT-4 几个百分点(请记住,GPT-4 在 2022 年完成了训练)。我认为这证明了用目前的方法让模型变得更好是非常困难的,而不是证明 Google DeepMind 的研究人员比 OpenAI 的研究人员“更糟糕”——这两家公司拥有世界上最好的人工智能人才,所以从字面上看,这是人工智能的巅峰。人类现在可以在人工智能上做什么。他们应该开始探索其他范式吗?我觉得事情正在发生变化,我们即将告别基于 Transformer 的语言模型的霸权。
也许更值得注意的是——即使并不令人惊讶——谷歌 DeepMind 对亲密性的拥抱(就像 OpenAI 和 Anthropic 一样)。他们没有分享有关训练或微调数据集的任何有价值的内容,也没有分享有关架构的任何有价值的内容。这表明,严格意义上来说,Gemini 与其说是一个科学项目,不如说是一个商业产品。这本身并不坏(取决于您是研究人员还是用户),只是不是 DeepMind 的真正目的。就像微软在 2019 年投资 OpenAI 迫使他们转向生产和产品市场契合策略一样,谷歌也在同样程度上利用 DeepMind 来实现这一目标。
回到现实,接下来是规划、代理和机器人。我预测在接下来的几个月/几年里,我们在这些更大的挑战上的进展将比我们在语言建模上看到的进展慢(记住莫拉维克悖论)。Hassabis 认为 Gemini 将展示我们以前从未见过的能力,但我认为与 OpenAI 已经拥有的相比,这些不会是真正的突破(在大的计划中)。哈萨比斯与牛顿讨论了这一点,所以我仍然很兴奋:“我认为我们会看到一些新功能。这是 Ultra 测试的一部分。我们正处于测试阶段——对其进行安全检查、责任检查,同时也看看如何对其进行微调。”
最后,尽管 Sundar Pichai 将这次发布称为“ Gemini 时代”的开始,但我认为 Google 的真正价值在于恢复他们年复一年失去的部分信任,当时一家拥有 800 名员工的初创公司屡次设法离开他们在后面。这是谷歌对所有声称根本无法超越的人的报复。这是它对 OpenAI 以及围绕 ChatGPT 和 GPT-4 无可挑剔的回击。我们将看看它是否对他们有效,更重要的是,它能持续多久。
免责声明
本文提供的信息仅供参考和一般信息目的。我们已尽一切努力确保信息的准确性和完整性,但不做明示或暗示的任何保证或陈述。读者在使用本信息前应仔细评估和判断。如果您对本文内容有任何疑问或发现侵权行为,请与我们联系以解决。
📣 感谢您阅读本文!
如果您发现本文对您有所帮助,请与您的朋友和家人分享,以使更多人受益。
- 作者:Inevitable AI
- 链接:https://www.Inevitableai.ltd/article/231207_p1
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。