
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄
背景
图 1:典型推荐系统中的多个用例
在电子商务、流媒体服务和社交媒体等大型现实世界推荐系统应用中,会训练多个机器学习模型来优化系统不同部分的项目推荐。对于不同的用例有单独的模型,例如通知(用户到项目的推荐)、相关项目(基于项目到项目的推荐)、搜索(查询到项目的推荐)和类别探索(类别到项目)。项目建议)(图1)。然而,这可能会迅速导致系统管理开销和维护大量专用模型的隐藏技术债务(Sculley 等人,2015)。这种复杂性可能会导致长期成本增加,并降低机器学习系统的可靠性和有效性(Ehsan & Basillico,2022)。
图 2 显示了这种具有模型扩散功能的 ML 系统的外观。通知、相关项目、搜索和类别探索等不同的用例具有不同的 UI 画布,用户可以在其中与之交互。适用于这些不同用例的机器学习系统通常会发展为具有多个离线管道,这些管道具有类似的步骤,例如标签生成、特征化和模型训练。在在线方面,不同的模型可能托管在具有不同推理 API 的不同服务中。然而,离线管道和在线基础设施有许多共同点,但这种设计没有利用这些共同点。
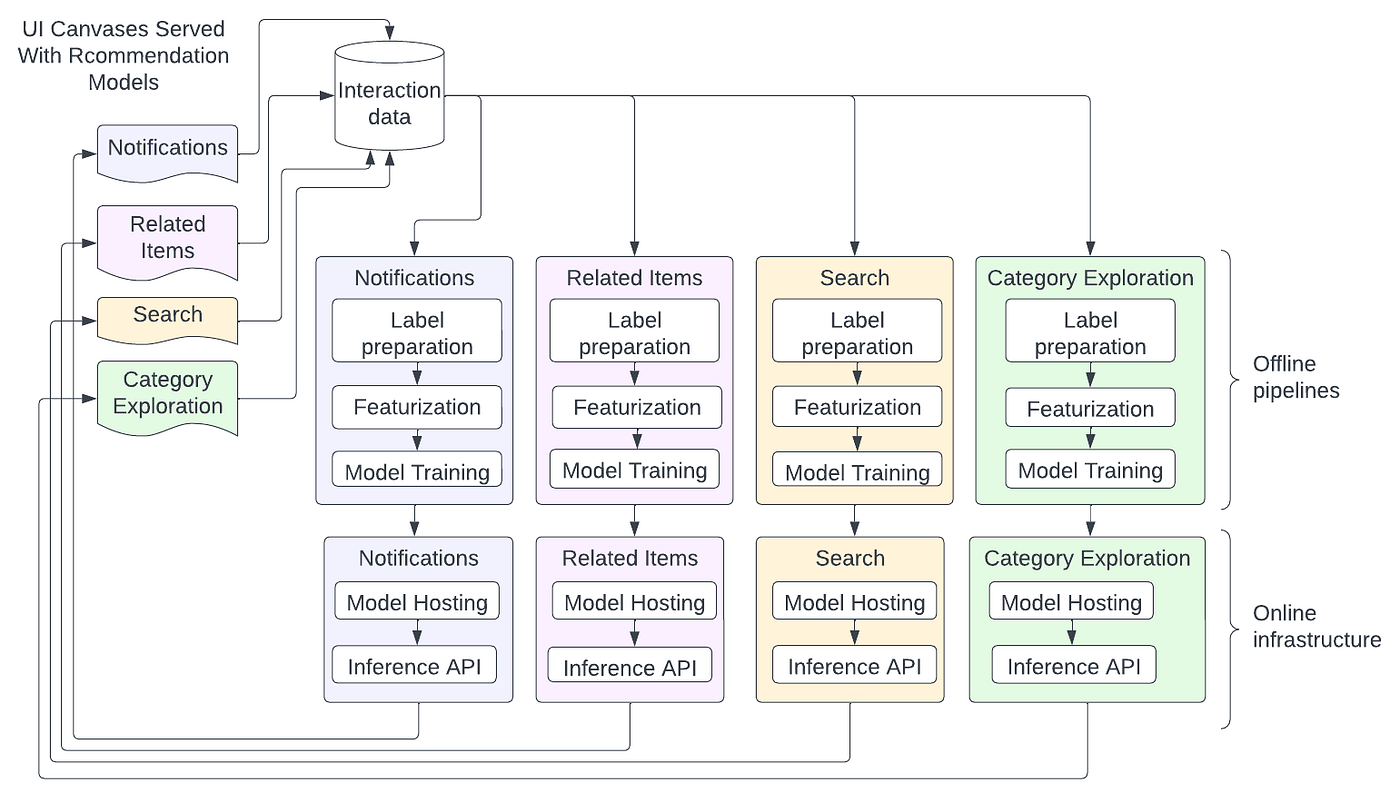
图 2:机器学习系统中的模型激增
在本博客中,我们描述了我们如何利用这些任务的共性来整合这些模型的离线和在线堆栈。这种方法不仅减少了技术债务,而且还通过利用从一项任务中获得的知识来改进另一项相关任务,从而提高了模型的有效性。此外,我们还注意到在多个推荐任务中有效实施创新更新方面的优势。
图 3 显示了整合的系统设计。在完成特定于用例的标签准备的初始步骤后,我们统一离线管道的其余部分并训练单个多任务模型。在在线方面,灵活的推理管道根据延迟、数据新鲜度和其他要求在不同环境中托管模型,并且模型通过统一的与画布无关的 API 公开。
图 3:整合的机器学习系统
离线设计
在离线模型训练管道中,每个推荐任务都映射到需要显示推荐的请求上下文。请求上下文架构根据具体任务而有所不同。例如,对于查询到项目的推荐,请求上下文将包含查询、国家/地区和语言等元素。另一方面,对于逐项推荐,请求上下文还将包括源项和国家/地区信息。请求上下文模式的组成经过定制,以满足每个推荐任务的要求。
离线管道根据以下阶段记录的交互数据来训练模型:
标签准备:清理记录的交互数据并生成(request_context,标签)对。
特征提取:为上面生成的(request_context,label)元组生成特征向量。
模型训练:基于(特征向量,标签)行训练模型。
模型评估:使用适当的评估指标评估训练模型的性能。
部署:使模型可用于在线服务。
为了模型整合,我们将统一的请求上下文设置为跨任务的所有上下文元素的并集。对于特定任务,缺失或不必要的上下文值将由哨兵(默认)值替换。我们引入一个 task_type 分类变量作为统一请求上下文的一部分,以告知目标推荐任务的模型。
在标签准备过程中,来自每个画布的数据被清理、分析并使用统一的请求上下文模式存储。然后将来自不同画布的标签数据通过适当的分层合并在一起,以获得统一的标签数据集。在特征提取中,并非所有特征都包含某些任务的值并填充适当的默认值。
在线设计
大规模服务单个 ML 模型会带来某些独特的在线 MLOps 挑战(Kreuzberger 等人,2022)。每个用例可能在以下方面有不同的要求:
- 延迟和吞吐量:
不同的服务级别协议 (SLA) 可保证延迟和吞吐量目标,从而提供最佳的最终用户体验。
- 可用性:
模型服务正常运行时间的不同保证,无需诉诸回退。
- 候选集
不同类型的项目(例如视频、游戏、人物等),可以根据用例特定的业务需求进一步策划。
- 预算:
模型推理成本的不同预算目标。
- 业务逻辑:
不同的预处理和后处理逻辑。
从历史上看,特定于用例的模型经过调整以满足独特的需求。在线 MLOps 的核心挑战是支持各种用例,而不会回归到模型性能的最低公分母。
我们通过以下方式应对这一挑战:
根据用例在不同的系统环境中部署相同的模型。每个环境都有“旋钮”来调整模型推理的特征,包括模型延迟、模型数据新鲜度和缓存策略以及模型执行并行性。
为消费系统公开通用的、与用例无关的 API。为了实现这种灵活性,API 支持异构上下文输入(用户、视频、类型等)、异构候选选择(用户、视频、类型等)、超时配置和后备配置。
得到教训
将 ML 模型合并为单个模型可以被视为软件重构的一种形式。与软件重构类似,对相关代码模块进行重组和整合以消除冗余并提高可维护性,模型整合可以被认为是将不同的预测任务组合到单个模型中,并利用共享的知识和表示。这样做有几个好处。
减少代码和部署占用空间
支持新的机器学习模型需要对代码、数据和计算资源进行大量投资。设置训练管道来生成标签、特征、训练模型和管理部署非常复杂。维护这样的管道需要不断升级底层软件框架并推出错误修复。模型整合是降低此类成本的重要杠杆。
提高可维护性
生产系统必须具有高可用性:必须快速检测并解决任何问题。机器学习团队通常会进行轮班值班,以确保操作的连续性。单一统一的代码库使随叫随到的工作变得更加容易。其好处包括几乎不需要或不需要进行待命上下文切换、工作流程的同质性、更少的故障点以及更少的代码行。
将模型改进快速应用到多个画布
通过构建具有多任务模型的整合机器学习系统,我们可以将一个用例中的进步快速应用到其他用例中。例如,如果针对特定用例尝试某个功能,则通用管道允许我们在其他用例中尝试该功能,而无需额外的管道工作。当为一个用例引入功能时,需要权衡其他用例的潜在回归。然而,在实践中,如果合并模型中的不同用例足够相关,那么这并不是问题。
更好的扩展性
将多个用例合并到一个模型中可以促进灵活的设计,在合并多个用例时需要额外考虑。因此,这种重要的可扩展性使系统能够面向未来。例如,我们最初设计模型训练基础设施是为了整合一些用例。然而,事实证明,整合这些多个用例所需的灵活设计对于在同一基础设施上加载新模型训练用例是有效的。特别是,我们包含可变请求上下文模式的方法简化了使用相同基础设施的新用例的训练模型的过程。
最后的想法
尽管机器学习系统整合并不是灵丹妙药,也可能并不适用于所有情况,但我们相信,在很多情况下,这种整合可以简化代码、实现更快的创新并提高系统的可维护性。我们的经验表明,对相似目标进行排名的合并模型会带来很多好处,但尚不清楚对完全不同的目标进行排名并具有截然不同的输入特征的模型是否会从这种合并中受益。在未来的工作中,我们计划为 ML 模型整合何时最合适建立更具体的指南。最后,NLP 和建议的大型基础模型可能会对 ML 系统设计产生重大影响,并可能导致系统级别的更多整合。
致谢
我们感谢 Vito Ostuni、Moumita Bhattacharya、Justin Basilico、Weidong Zhu 和 Xinran Waibel 对机器学习系统的贡献。还要感谢 Anne Cocos 对之前草案的宝贵反馈。
- 作者:Inevitable AI
- 链接:https://www.Inevitableai.ltd/article/share136
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。