type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄

机器学习是一个庞大的领域,可以理解的是,很难找到一个来源来概述目前处于技术前沿的模型和技术。话虽如此,本文更多的是概念性探索,而不是对每个模型的具体科学分析。事实上,如果可能的话,我实际上建议更深入地研究每一项。我还想提供这些模型的使用示例,因为在我看来,理论应该始终与实践联系起来。如果我遗漏任何信息,请随时提供反馈并请求更多信息。
CNN
那么有何不同呢?
首先,让我简要概述一下什么是神经网络。
简而言之,神经网络是处理输入数据并产生输出的节点的“地图”。它由将一组节点映射到另一组节点的层组成,将输入传播并转换为结果。传播是通过权重完成的,权重是在每个传播步骤中改变我们的输入以产生我们想要的结果的值。在每个传播步骤之后,都会施加偏置。权重和偏差是我们真正想要的:它们是训练网络时改变的数字。
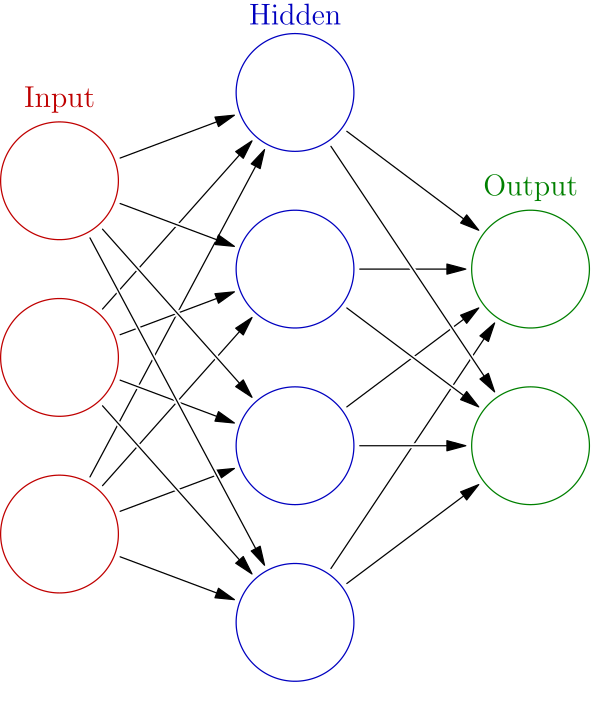
CNN 有什么特别之处?CNN 的独特之处在于它在层堆栈中使用了卷积 层。这并不是说 CNN 不能有其他类型的层(通常是这样),但卷积使其变得特殊。以下是该层的工作原理。
如果您将图像中的每个像素想象为一个亮度值,那么您的图像就变成了一个二维数字矩阵。卷积将采用该矩阵并通过对其应用内核来生成输出矩阵。内核只是一个较小的矩阵,就像图像中每个区域的过滤器一样。
较小的矩阵“步进”通过图像的较大矩阵以产生输出矩阵。

这里有一些关键想法。
1)内核以某种方式应用于图像的每个像素及其周围区域,但它始终保持不变。这是因为内核旨在检测该像素区域内的模式或特征。
2)内核通常比图像本身小得多,这对训练有很大帮助。
3)内核背后的想法是,任何图像都只是我们可以分解的一组模式。例如,假设我们有一张脸。想象一下,有一个能够检测圆圈的内核。其输出将在图像顶部附近包含 2 个亮点(它检测到的眼睛)。现在想象一下,有另一个可以检测靠近的两条线。输出将在底部(它检测到的嘴)附近有一个亮点。最后,想象一下最终应用的内核可以检测到 2 个圆圈和底部 2 条线的形成。好吧,那么它就会认出这张脸了。
4)卷积层可以应用多个这样的内核来生成多个新图像。然后将它们堆叠在一起并在网络中转发。然后另一个卷积层将应用另一组内核。
5)CNN 通常还包含池化层,用于减小图像大小和复杂性。
显然,我在这里错过了更多细节和数学,但 CNN 背后的主要直觉在于内核。
使用 CNN 的一些流行工具和产品包括 Google Photos、DeepMind 的 AlphaGo 和 Tesla 的 Autopilot 系统。
RNN
正如您所见,CNN 主要用于图像处理。另一方面,RNN 主要用于 NLP(自然语言处理)和其他一些领域,例如时间序列分析。为了理解 RNN 背后的架构,我们首先强调一下使用简单神经网络进行 NLP 的一些问题。
让我们看一个标准的 NLP 问题——文本自动完成。我们模型的输入是一段文本,输出是另一段文本。问题是我们的输入是可变大小的(可以是几个单词或很多单词),而简单的神经网络通常具有固定的输入大小。另一个问题是捕获输入中单词之间的复杂关系以产生正确的输出。请记住,英语中有数千个单词,句子中这些单词的顺序并不一定会改变含义。那么,如何确保“The fluffy cat come here on Sunday”这句话与“On Sunday, the catwhich was fluffy come here”相似,但又不同于“The Sunday come here on a fluffy cat”呢?
RNN 背后的直觉来自于信息如何流经它们。让我们以一个句子为例,看看 RNN 如何处理它——“The cat eats”。
让我们把这个句子看成一个单词序列——“The”、“cat”和“eats”(实际上,它可能会被表示为一系列向量)。RNN 现在将按顺序处理这个序列(这就是名称中“Reccurent”部分的来源)。首先,它将接收单词“The”,并通过将“The”通过它自己的一组权重和偏差进行管道传输来产生一些输出x1。然后,它将使用 x1 和序列中的下一个单词“cat”,通过同一组权重和偏差进行管道传输,以获得下一个输出x2。然后,它将采用 x2 和序列中的下一个单词“eats”,以获得下一个输出x3。通过这种方式,您可以看到 RNN 如何获取之前的输出和下一个输入,以产生一些新的输出。RNN 的当前“状态”称为隐藏状态。

如何用它来预测你提问后的下一个单词?好吧,想象一下每个输出 — x1、x2、x3 实际上代表一个新单词。我们可以训练网络,使输出实际上是对下一个单词的预测。那么,让我们再次看看正在处理的句子。
“The” -> 通过我们的模型进行管道传输 -> 产生 x0,我们训练我们的模型,使得 x0 可以正确外推为“cat”
“cat”和之前的输出 x0 -> 通过我们的模型进行管道传输 -> 生成 x1,训练后 x1 可以正确外推为“eats”
“吃”和之前的输出 x1 -> 通过我们的模型进行管道传输 -> 产生 x2。我们发现 x2 现在代表“tuna”这个词!我们可以将其用于下一个“输入”
“tuna” 和之前的输出 x2 -> 通过我们的模型进行管道传输 -> 生成 x3...等等
RNN 背后的主要直觉在于:
- RNN 始终通过此隐藏状态
跟踪之前看到的内容,并捕获单词之间的关系或任何与此相关的顺序数据。
- 相同的模型
反复应用于序列的每个部分,这使得 RNN 可以进行训练(而不是让一个巨大的模型立即处理整个输入)
在这里,您可能已经可以预见到这种方法的一些问题。一旦文本变长,我们最初的几个单词几乎对当前的隐藏状态没有贡献,这是不理想的。此外,我们被迫按顺序进行此处理,因此我们的处理和训练速度都受到算法本身的限制。
尽管如此,这些强大的模型还有更多功能,所以我鼓励您更深入地研究!
使用 RNN 的一些流行工具和产品包括 Google Translate、OpenAI 的 GPT2 和 Spotify 的推荐系统。
Transformers
Transformers!当前机器学习世界的风潮。GPT4和BERT(Google自己的高级语言模型)都是基于Transformer架构的。那么它们是关于什么的呢?
嗯,变压器主要用于 NLP 问题,就像 RNN 一样,因此它们必须解决我之前描述的与语言处理相关的类似问题。然而,有一些关键想法可以与 RNN 不同地缓解这些问题。
位置编码
虽然语言中的序列重要性通过其隐藏状态自然地保留在 RNN 中,但 Transformer 将此信息直接嵌入到输入中。将位置编码添加到单词嵌入(单词的向量表示)中,确保捕获句子中每个单词的位置。因此,“狗”的表示会根据其在文本中的位置进行修改。
巨大的训练数据集
为了利用位置编码的优势,变压器必须在巨大的数据集上进行训练。数据中捕获了词序的这些差异,因此如果没有看到顺序和词类型的各种不同可能性,模型的运行效果将不佳。
自我关注
模型学会更多地“关心”某些单词以及它们与输入中其他单词的关系。毕竟,有些单词在预测或翻译中会具有更多的意义和力量,尤其是与其他单词组合在一起时。它是如何学会做到这一点的?同样,它是通过大量的训练数据集大小及其架构来实现的。
然而,变压器背后的架构有点复杂,很难在这么短的文章中解释清楚。尽管如此,我还是会尽力为您描绘一幅非常高水平的图画。Transformer 由解码器和编码器组成。编码器由一堆相同的层组成,其作用是处理文本并为解码器提供输入,解码器将捕获文本的最重要信息。解码器的作用是获取该输入并产生我们想要的输出,其过程与一堆相同层的过程类似。
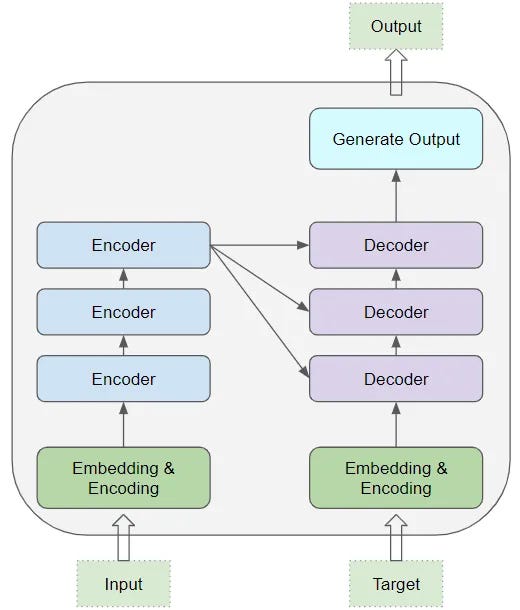
我强烈建议深入研究这个主题,尤其是 Transformer 核心的“自我关注”机制。
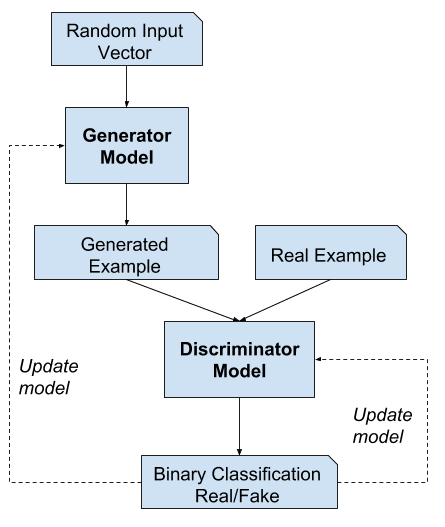
GAN
GAN(生成对抗网络)从根本上讲是两个相互竞争的对立模型。GAN 通常指的是训练这些模型的学习方法,而不是模型本身。事实上,这两种模型的架构对于概念本身来说并不是太重要,只要一个是生成式的,另一个是分类器即可。
让我们首先描述训练模型的标准监督学习技术。
1)我们向模型提供一些输入,它会产生一些输出
2)我们将此输出与所需输出进行比较,并以某种方式更新模型以做得更好
然而,当我们想要创建一个生成现实输出的模型时,就会出现一个问题,该输出不一定与我们拥有的任何类型的输出相同(例如图像生成或音乐生成)。这就是 GAN 的用武之地。在 GAN 中,我们有两个模型:生成器模型和判别器模型。
以生成图像的生成器模型为例。我们首先提示该模型生成一些假图像,然后也找到一些真实图像。然后,我们将所有这些图像的组合输入到我们的鉴别器模型中,该模型将它们分类为真或假。如果我们的生成器模型表现良好,鉴别器模型就会被难住,并且大约有一半的时间会得到正确的答案。显然,一开始情况并非如此(我们的判别器通常会稍微进行预先训练),因此以监督学习的方式(我们自己知道哪些图像是真实的或假的),我们训练判别器模型以做得更好下次。我们还可以训练生成器模型,因为我们知道它的欺骗能力如何判别器模型。当我们能够生成能够在 50% 左右的时间欺骗判别模型的图像时,训练就完成了。