
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄
动手实践!ChatGPT 如何管理令牌?

您是否想知道 ChatGPT 背后的关键组件是什么?
我们都被告知同样的事情:ChatGPT 会预测下一个单词。但实际上,这种说法有一点谎言。它不会预测下一个单词,ChatGPT 会预测下一个标记。
代币?是的,令牌是大型语言模型 (LLM) 的文本单位。
事实上,ChatGPT 在处理任何提示时执行的第一步是将用户输入拆分为标记。这就是所谓的分词器的工作。
在本文中,我们将通过 OpenAI 使用的原始库(即库)的实际操作来揭示 ChatGPT 分词器如何工作
tiktoken。TikTok-en…够有趣的:)
让我们深入了解标记器执行的实际步骤,以及它的行为如何真正影响 ChatGPT 输出的质量。
分词器如何工作
在《掌握 ChatGPT:使用法学硕士进行有效总结》一文中,我们已经了解了 ChatGPT 分词器背后的一些奥秘,但让我们从头开始。
分词器出现在文本生成过程的第一步。它负责将我们输入到 ChatGPT 的文本片段分解为单个元素(标记),然后由语言模型处理以生成新文本。
当分词器将一段文本分解为标记时,它会根据一组旨在识别目标语言的有意义单元的规则来完成此操作。
例如,当给定句子中出现的单词是相当常见的单词时,每个标记很可能对应一个单词。但是,如果我们使用不常用单词的提示,例如“提示作为强大的开发人员工具”这句话,我们可能无法获得一对一的映射。在这种情况下,单词提示在英语中仍然不常见,因此它实际上被分解为三个标记:“'prom”、“pt”和“ing”,因为这三个是常见的字母序列。
让我们看另一个例子!
考虑以下句子:“我想吃花生酱三明治”。如果分词器配置为根据空格和标点符号分割标记,则它可能会将此句子分解为以下标记,总字数为 8,等于标记计数。
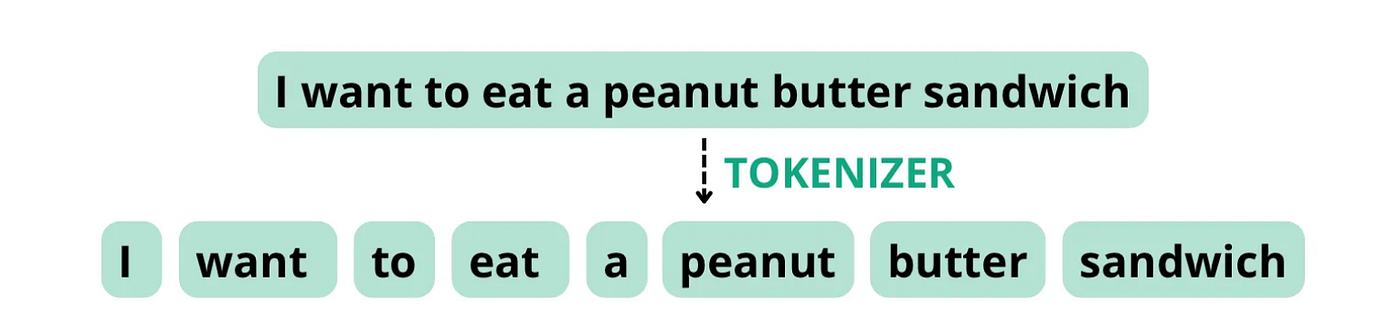
然而,如果分词器将“花生酱”视为复合词,因为这些成分经常一起出现,它可能会将句子分解为以下标记,总字数为 8,但标记数为7 .
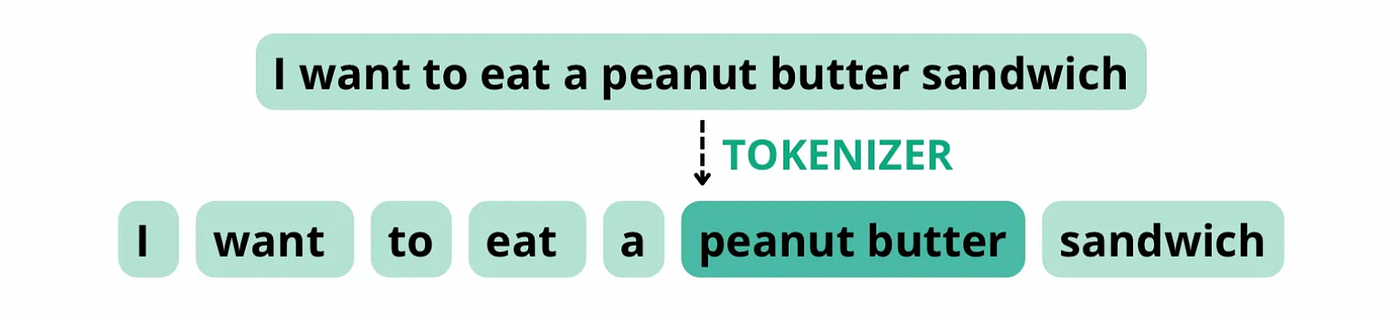
在 ChatGPT 和令牌管理的上下文中,术语编码和解码是指将文本转换为模型可以理解的令牌(编码)并将模型的完成转换回人类可读文本(解码)的过程。
tiktoken库
了解 ChatGPT 分词器背后的理论是必要的,但在本文中,我也想重点介绍一些实践启示。
ChatGPT 实现使用该
tiktoken库来管理令牌。我们可以像任何其他 Python 库一样运行它:一旦安装完毕,就可以非常简单地获得与 ChatGPT 使用的相同的编码模型,因为有一种
encoding_for_model()方法。从名称推断,此方法会自动加载给定模型名称的正确编码。第一次针对给定模型运行时,需要互联网连接来下载编码模型。以后的运行不需要互联网,因为编码已经预先缓存。
对于广泛使用的
gpt-3.5-turbo模型,我们可以简单地运行:输出
encoding是一个标记生成器对象,我们可以使用它来可视化 ChatGPT 如何实际看到我们的提示。更具体地说,该
tiktoken.encoding_for_model函数专门为模型初始化一个标记化管道gpt-3.5-turbo。该管道处理文本的标记化和编码,为模型的使用做好准备。需要考虑的一个重要方面是标记是数字表示。在我们的“提示作为强大的开发工具”示例中,与提示一词相关的标记是“'prom”、“pt”和“ing”,但模型实际接收的是这些序列的数字表示。
不用担心!我们将在实践部分看到它是什么样的。
编码类型
该
tiktoken库支持多种编码类型。事实上,不同的gpt模型使用不同的编码。这是最常见的表格:
编码——动手实践!
让我们继续尝试对我们的第一个提示进行编码。给出提示“tiktoken 太棒了!” 和已经加载的
encoding,我们可以使用该方法encoding.encode将提示拆分为标记并可视化它们的数字表示:是的,确实如此。输出
[83, 1609, 5963, 374, 2294, 0]似乎没有多大意义。但其实,有些东西一看就猜到了。知道了?
长度!我们很快就可以看到我们的提示“tiktoken很棒!” 被分成6个令牌。在这种情况下,ChatGPT 不会根据空格分割此示例提示,而是根据最常见的字母序列分割此示例提示。
在我们的示例中,输出列表中的每个坐标对应于标记化序列中的特定标记,即所谓的标记 ID。令牌 ID 是根据模型使用的词汇表唯一标识每个令牌的整数。ID 通常映射到词汇表中的单词或子单词单元。
让我们将坐标列表解码回来,以仔细检查它是否与我们原来的提示相对应:
该
.decode()方法将标记整数列表转换为字符串。尽管该.decode()方法可以应用于单个令牌,但请注意,对于不在utf-8边界上的令牌来说,它可能是有损的。现在您可能想知道,有没有办法查看各个令牌?
让我们一起努力吧!
对于单个标记,该
.decode_single_token_bytes()方法将单个整数标记安全地转换为其表示的字节。对于我们的示例提示:注意
b字符串前面的 表示该字符串是字节字符串。对于英语,一个标记大致平均对应于大约四个字符或大约四分之三的单词。了解文本如何拆分为标记非常有用,因为 GPT 模型以标记的形式查看文本。了解文本字符串中有多少个令牌可以为您提供有用的信息,例如字符串是否太长而无法让文本模型处理,或者 OpenAI API 调用的成本是多少,因为使用量是按令牌定价的,等等。
比较编码模型
正如我们所看到的,不同的模型使用不同的编码类型。有时,模型之间的代币管理可能存在巨大差异。
不同的编码在分割单词、分组空间和处理非英语字符的方式上有所不同。使用上面的方法,我们可以比较
gpt几个示例字符串上可用的不同模型的不同编码。让我们比较一下上表的编码(
gpt2、p50k_base和cl100k_base)。为此,我们可以使用以下函数,其中包含迄今为止我们所看到的所有内容:该
compare_encodings函数采用 anexample_string作为输入,并使用三种不同的编码方案比较该字符串的编码:gpt2、p50k_base和cl100k_base。最后,它打印有关编码的各种信息,包括令牌数量、令牌整数和令牌字节。让我们尝试一些例子!

在第一个示例中,尽管
gpt2和p50k_base模型通过将数学符号与空格合并在一起来在编码上达成一致,但编码cl100k_base将它们视为单独的实体。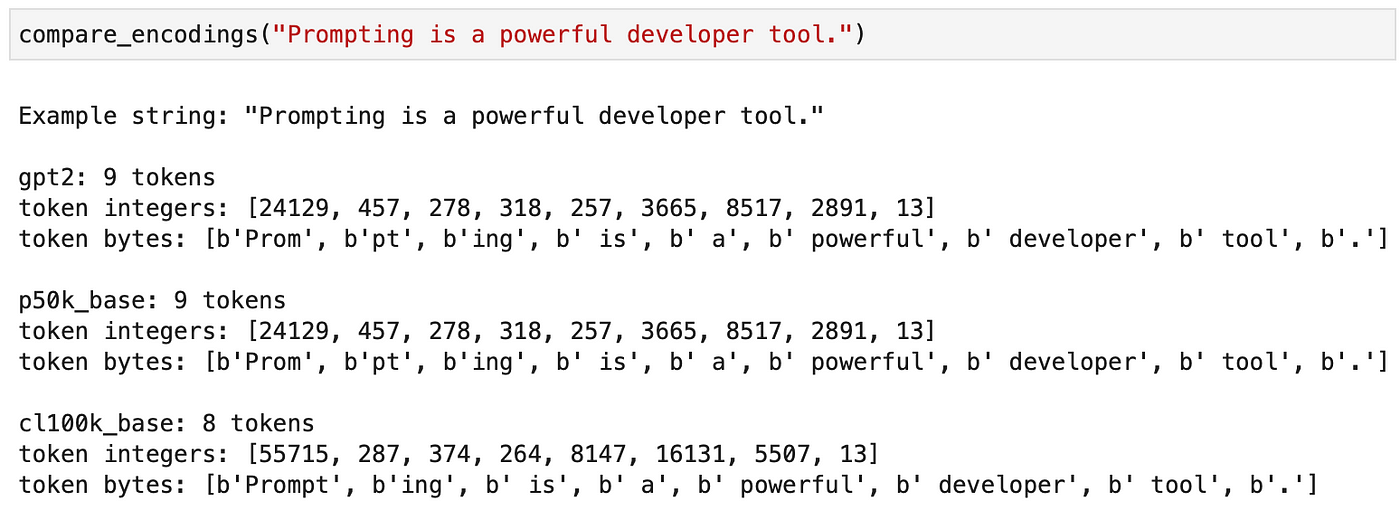
在此示例中,对单词Prompting进行标记的方式还取决于所选的编码。
分词器限制

这种对输入提示进行标记的方式有时会导致某些 ChatGPT 完成错误。例如,如果我们要求 ChatGPT 以相反的顺序写出单词 lollipop,它就会出错!
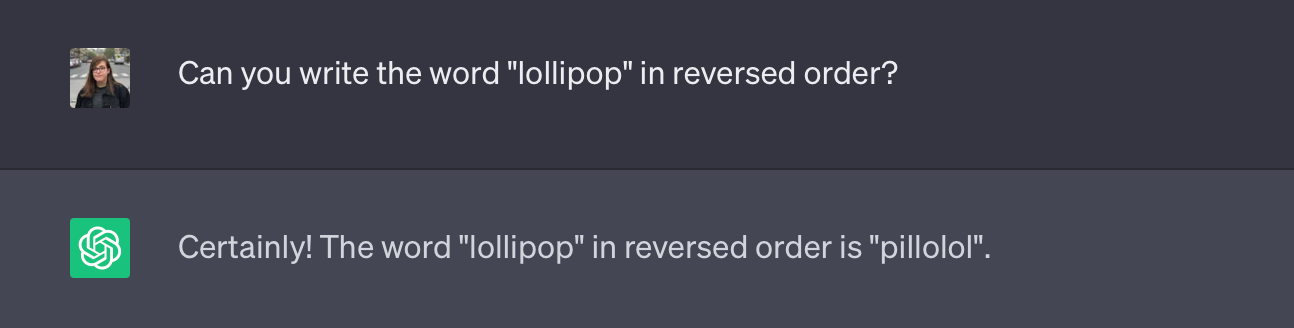
这里发生的是,分词器实际上将给定的单词分解为三个标记:“l”、“oll”和“ipop”。因此,ChatGPT 不会看到单个字母,而是看到这三个标记,这使得正确以相反顺序打印单个字母变得更加困难。
意识到这些限制可以让您找到解决方法来避免它们。在这种情况下,如果我们在各个字母之间的单词中添加破折号,我们可以强制分词器根据这些符号分割文本。通过稍微修改输入提示,它实际上做得更好:

通过使用破折号,模型可以更轻松地看到各个字母并以相反的顺序打印出来。因此请记住这一点:如果您想使用 ChatGPT 玩文字游戏,例如Word或Scrabble,或者围绕这些原则构建应用程序,这个巧妙的技巧可以帮助它更好地查看单词的各个字母。
这只是一个简单的示例,其中 ChatGPT 标记生成器导致模型在一个非常简单的任务中失败。您还遇到过其他类似的案例吗?
概括
在本文中,我们探讨了 ChatGPT 如何查看用户提示并处理它们,以根据在训练过程中从大量语言数据中学到的统计模式生成完成输出。
通过使用该
tiktoken库,我们现在可以在将任何提示输入 ChatGPT 之前对其进行评估。这可以帮助我们调试 ChatGPT 错误,因为通过稍微修改我们的提示,我们可以使 ChatGPT 更好地完成任务。作者:安德里亚·巴伦苏埃拉
- 作者:Inevitable AI
- 链接:https://www.Inevitableai.ltd/article/share75
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。