
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄
使用带有免费 API 令牌的 Python、Streamlit 和 Hugging Face 模型,根据您的图片创建音频故事。

我们被人工智能模型和工具包围:更好的说法是,对于我们这些追随法学硕士发展的人来说,我们几乎已经超负荷了。
但你不觉得我们被抛在后面了吗?大公司和工具都隐藏在黑匣子后面,我们无权了解它们是如何运作的。
在本文中,我想与您一起探索一种仅使用开源和免费工具的多模式人工智能方法。我们破解这个过程,并将其分解为简单的步骤:然后我们学习如何自己做。
我们要创建的 Python-Streamlit 应用程序将我们的一张照片作为输入:Hugging Face 模型将识别描述照片的文本,并根据它生成一个短故事。之后,我们将根据该短篇故事生成音频。很酷,不是吗?
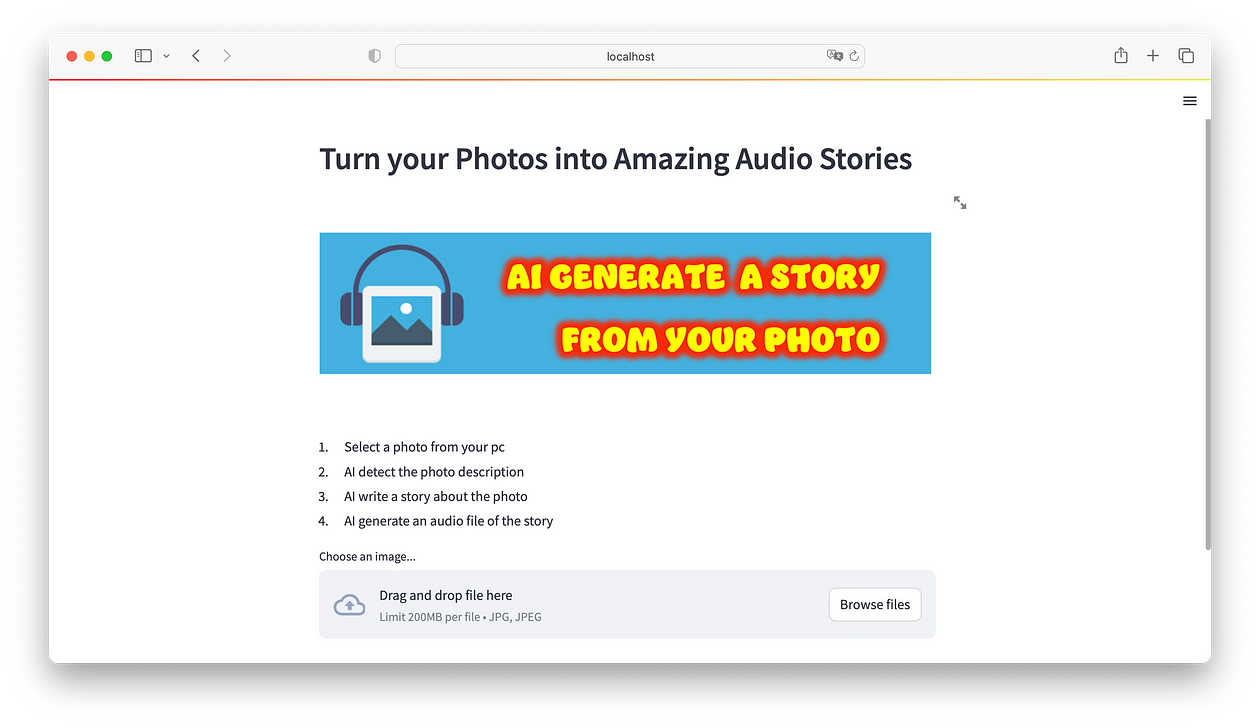
这里是我们要做的事情的细分:
自己学习如何做有很多好处:你了解官方文档的流程;您也可以在其他上下文中重用该函数。例如,根据描述对照片进行分类,或根据提示创建故事,甚至创建有声读物!
废话不多说,让我们开始吧
0.创建虚拟环境
我们不必安装很多库。作为一个好的实践,让我们创建一个虚拟环境来处理这个项目。
创建一个全新的目录(我的是AI-yourVideoStory)并运行 venv 创建指令:
激活虚拟环境:
1.安装所需的依赖项并获取 Hugging Face API 令牌
激活 venv 后,运行以下 pip 安装所需的软件包:
正如您所看到的,我们没有安装pytorch或tensorflow:这是因为我们将仅在免费的 Hugging Face 模型上使用 API 推理。为此,您需要在 Hugging Face 上注册并创建 API 令牌(您向法学硕士发出 API 请求的个人授权密钥)。
在API 推理的官方 Hugging Face 页面上,我们提供了获取 API 令牌的说明。
但什么是 🤗 托管推理 API?API是应用程序编程接口的缩写,是一组规则和协议,允许各种应用程序相互通信,即使它们是用不同的语言编写的。
因此,让我们在 Hugging Face 上创建一个帐户(如果您还没有),然后我们将创建我们的第一个 API 令牌
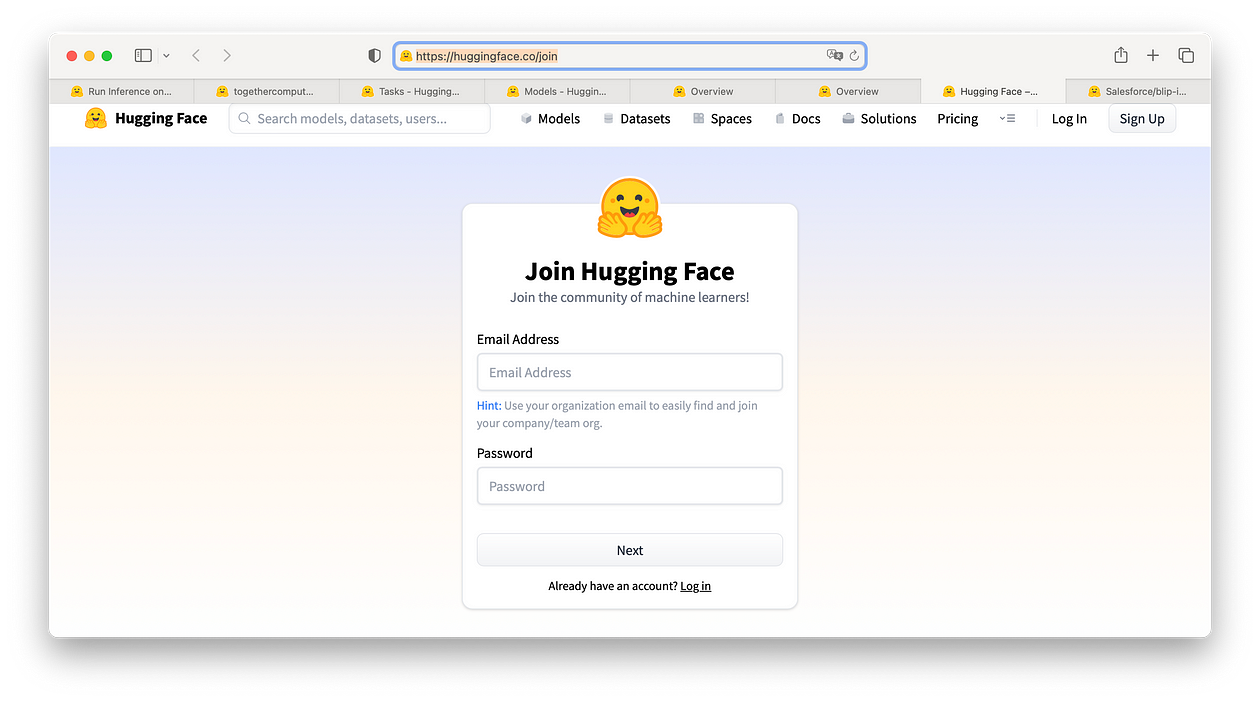
登录后,在 Hugging Face 配置文件设置中获取用户访问权限或 API 令牌。
您应该看到一个令牌
hf_xxxxx(旧令牌是api_XXXXXXXX或api_org_XXXXXXX)。记住!如果您在向 API 发送请求时未提交 API 令牌,您将无法在私有模型上运行推理。
在主目录中创建一个新的 python 文件并将其命名为app.py
现在,为了验证一切正常,让我们导入库并运行它:
保存它,然后在激活venv的情况下从终端窗口运行
如果你什么也没得到......意味着它工作正常😁
注意:我们还导入 Langchain,因为 Hugging Face 尚不支持文本生成推理管道:🦜️🔗 Langchain 将为我们解决这个问题。
我们都准备好了。
2.创建照片转文字AI功能
在我们的app.py中,我们可以开始创建一些函数。我们将为每项任务创建一个函数:一个用于图像到文本,一个用于文本生成,最后一个用于文本到语音。
导入后遵循以下代码:
我们使用 HF 令牌设置一个字符串变量,并为与任务相关的模型创建一个字符串(在本例中为 Image2Text)。
图像到文本任务位于 Hugging Face Multimodal 模型中。
在 Hugging Face 的模型页面上,我们可以只过滤多模式/图像到文本任务的模型:在最受欢迎的模型中,让我们以著名的 blip-base 为例
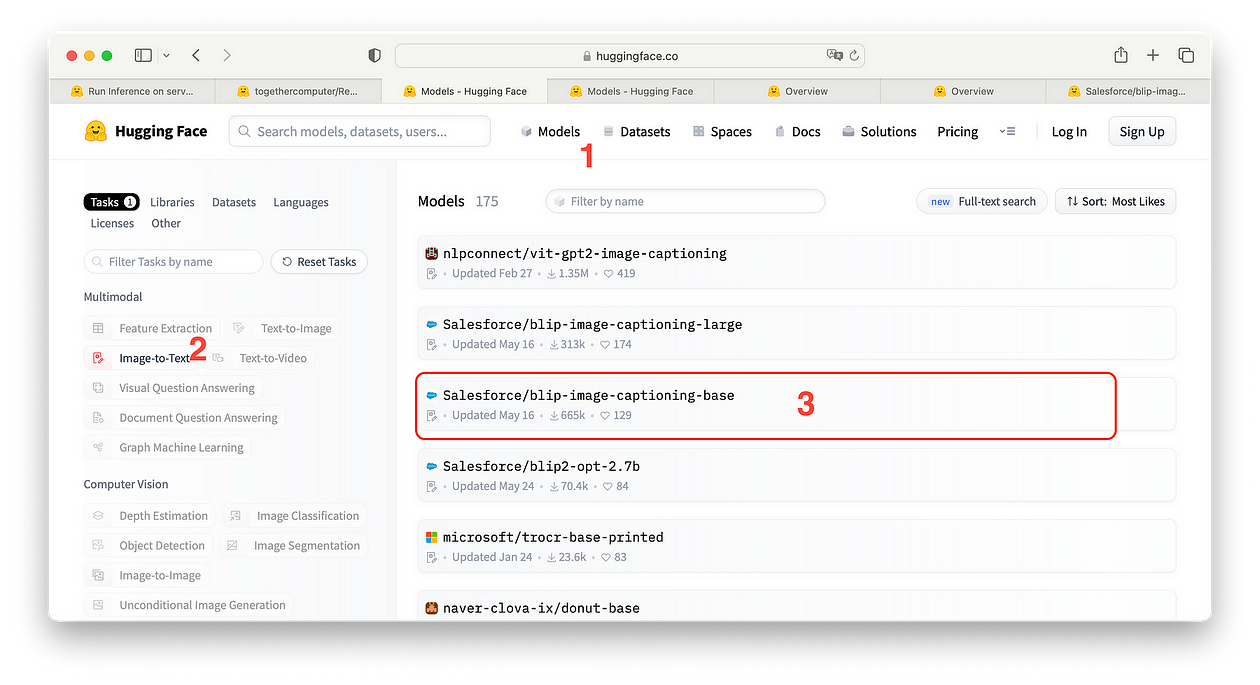
Salesforce/blip-image-captioning-base
当您单击它时 (3),模型卡页面将打开,其中包含大量说明和快速启动代码。为了进行推断,无论如何,我们遵循 API 的 Hugging Face 指南的说明,仅更改模型名称:您只需单击复制图标即可,如图所示
单击复制图标
我们的函数现在有了一个模型,我们发送带有以下说明的请求:
我们的函数将接受本地图像文件(称为url)并返回描述该图像的文本。
你的app.py应该是这样的:
出于测试目的,我们将使用此图像(您也可以在 GitHub 存储库上找到它)

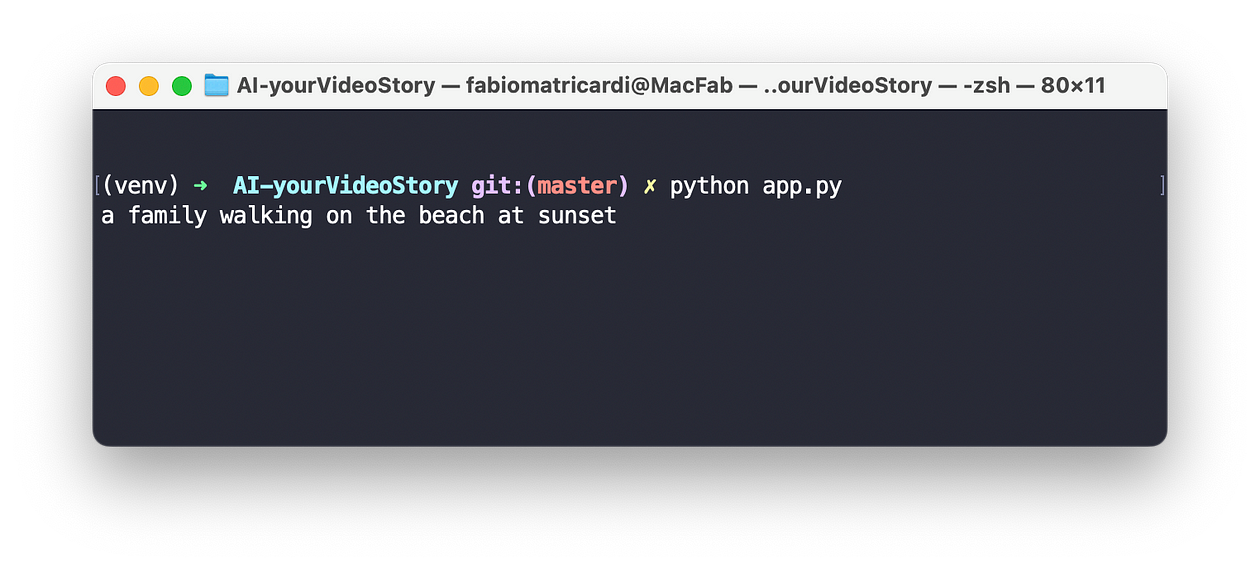
下载项目主文件夹中的图像(我的是AI-yourVideoStory),保存 python 文件并激活 venv,运行
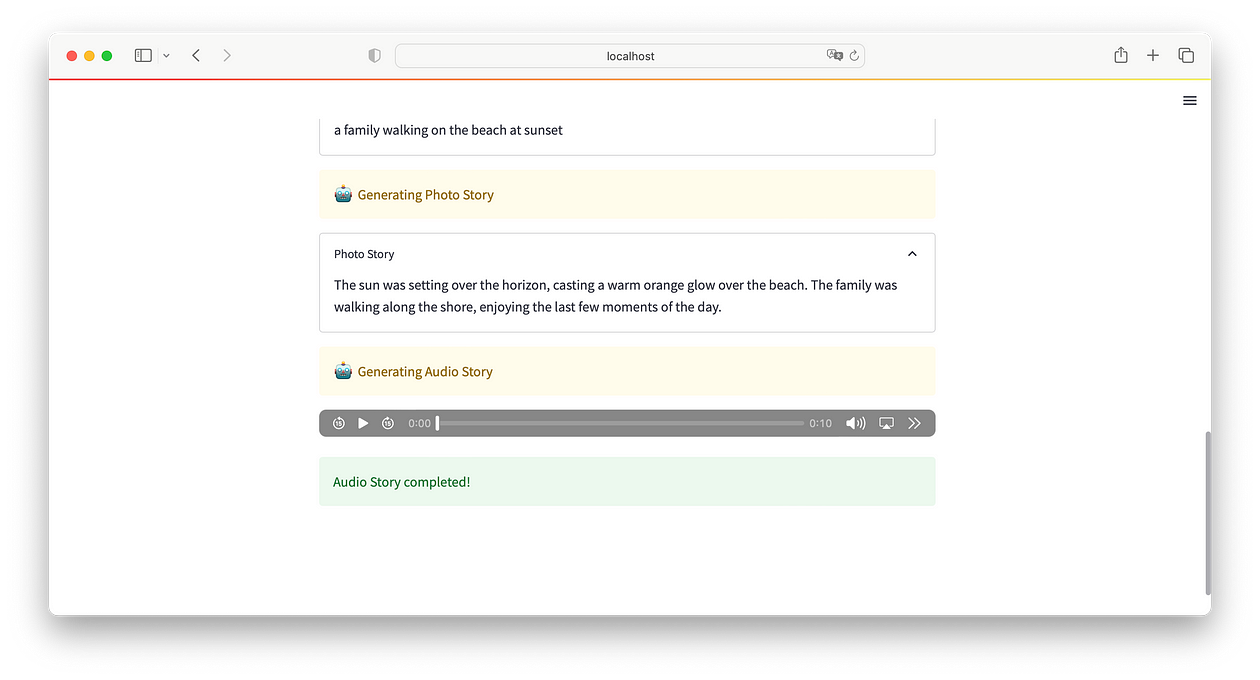
您应该得到以下内容
3.根据文本创建人工智能生成的故事
我们的 imageToText 函数检索到的照片描述将是我们故事生成的起点。
我告诉你:使用 Hugging Face 模型进行文本生成推理并不是一件容易的事情!首先,许多执行模型都禁用了 API:其次,文本生成推理根据您选择的模型遵循不同的规则。
我测试了其中的 20 个,最终决定选择Togethercomputer/RedPajama-INCITE-Chat-3B-v1主要基于OpenAssistant LLM 的模型之一。Open Assistant 是由 LAION 和世界各地有兴趣将该技术带给每个人的个人组织的一个项目。他们的座右铭是
我们相信我们可以创造一场革命。就像稳定扩散帮助世界以新的方式创作艺术和图像一样,我们希望通过提供令人惊叹的对话式人工智能来改善世界。
模型卡确实很有帮助,因为它为我们提供了提示的提示。
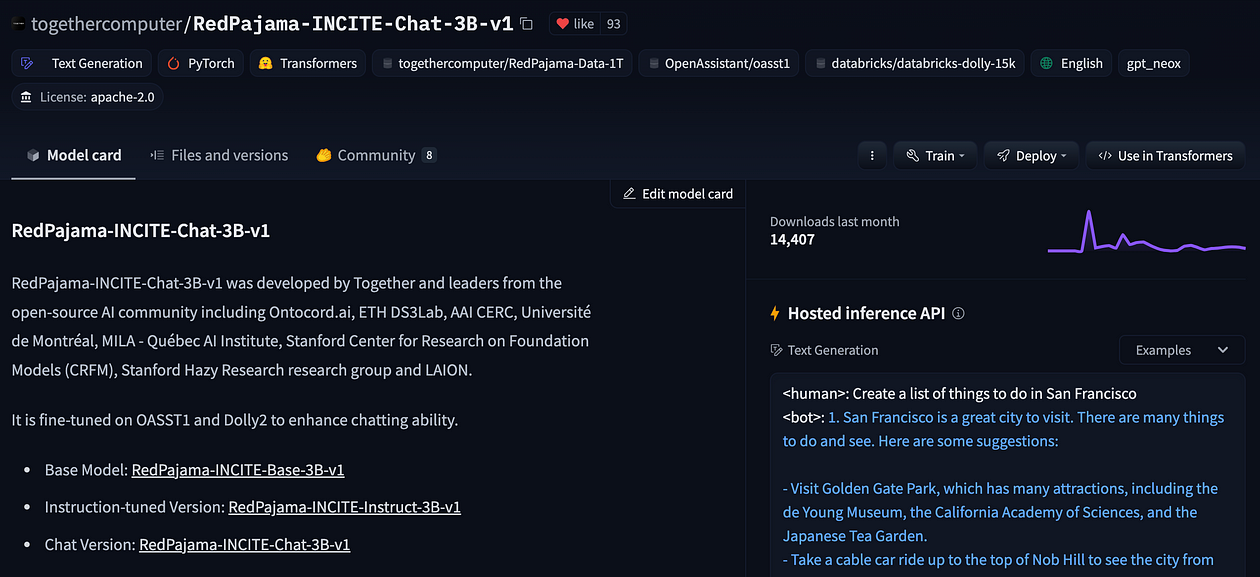
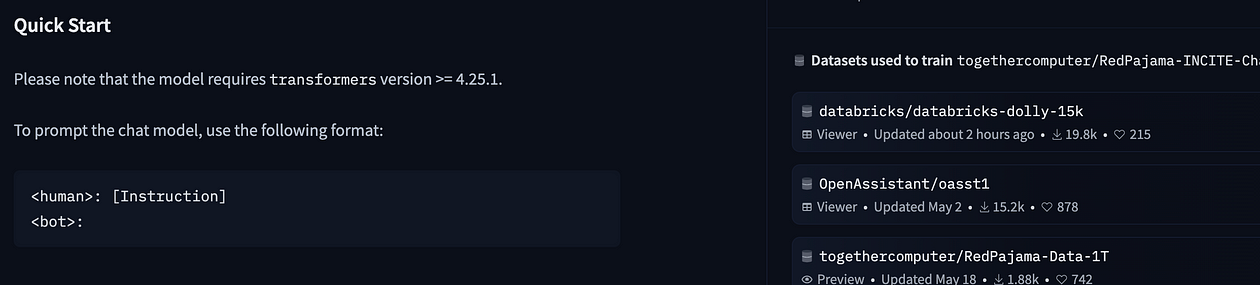
您已经可以在右侧面板上看到模型所需的结构:如果您将模型卡向下滚动到“快速启动”部分,也会清楚地说明:
我们将创建一个函数,使用 LangChain 作为文本生成推理的网关,指定一个类似于上面给出的提示。
LangChain 需要一种不同的方法来传递 HuggingFace API 令牌:我们使用 将其
os.environ["HUGGINGFACEHUB_API_TOKEN"]存储为环境变量。该函数将接受模型 (RedPajama-INCITE-Chat-3B-v1) 和基本文本(用于生成短篇故事的文本)作为位置参数。
正如您所看到的,我们的提示模板遵循快速入门部分的说明:我们仅添加基本文本变量以在基本指令中包含我们要完成的任务的详细信息
为了让您了解生成时间,有一些控制台打印指令(例如用于验证生成状态的小检查点)。
现在函数已经准备好了,让我们给出参数:
保存 python 文件并激活 venv,运行
您应该得到以下内容

您可能已经注意到这个故事要长得多。这就是为什么我们将其分成几个段落,并且只采用第一个:对于故事来说已经足够了
这一代人的速度很快,不是吗!?但要记住!这可能需要更长的时间,具体取决于 Hugging Face 中心推理服务器的流量有多少。
4.创建一个函数来从故事中生成音频文件
我们正在参加最后一场活动。现在我们有了故事,我们可以使用文本转语音模型来为我们生成音频。在“拥抱脸部模型”部分,向下滚动左侧面板以使用“文本转语音”选项过滤音频任务。
您可以尝试任何一种流行的声音:我选择espnet/kan-bayashi_ljspeech_vits因为我真的很喜欢自然的声音。
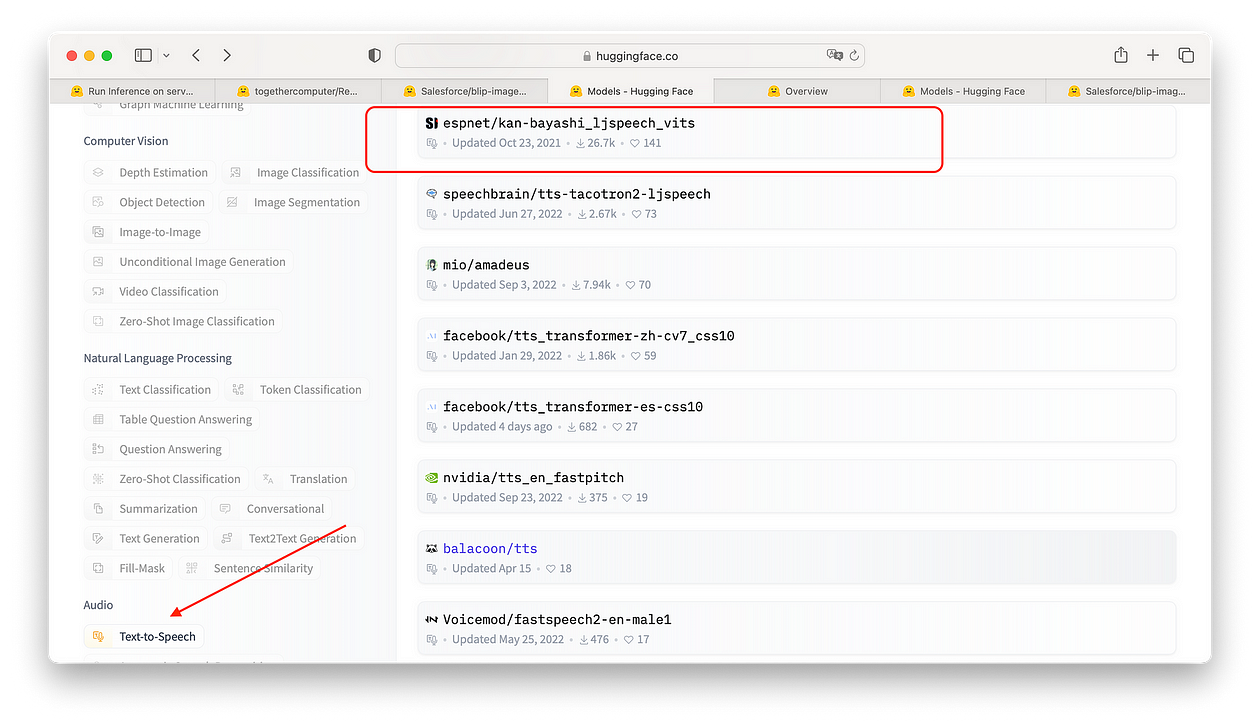
拥抱面部文本转语音任务模型
在模型卡页面上没有太多使用模型的指示:我们能做什么?
我们有两个选择!让我们看看他们:
- 托管推理 API
- 您可以使用快速推理 API 进行原型设计

型号卡用于
espnet/kan-bayashi_ljspeech_vits当您单击“部署/推理 API”按钮时,您将获得一个可供您使用的代码片段:如果您使用 HF 帐户登录,则会向您显示可用的 API 访问令牌,并与代码一起复制(无需任何努力)根本……!)
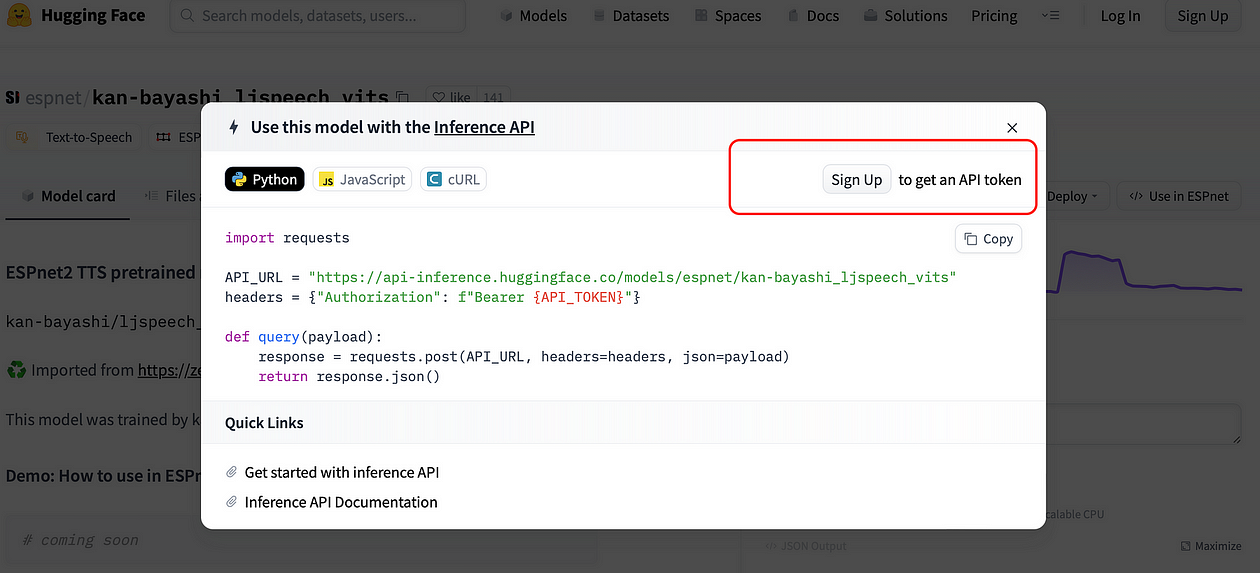
未登录时代码被截断
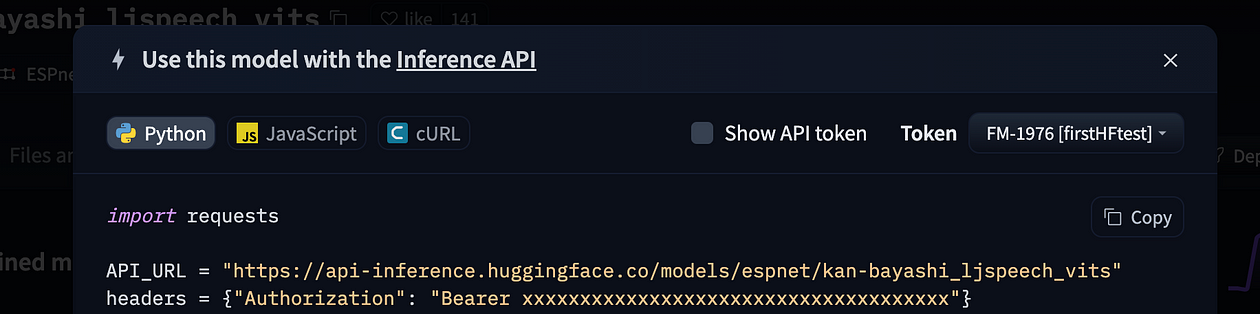
登录时的代码片段:您的令牌将与代码一起复制到剪贴板中
因此,让我们使用requests方法创建一个用于生成文本到语音的函数:我们将在标头中包含一个带有yourHFtoken的 f 字符串(如果不包含,API 请求将被拒绝)。
正如您所看到的,这非常简单:我们获得对请求的响应,并将其写入 .flac 音频文件。但什么是 FLAC'?
FLAC(免费无损音频编解码器)是一种用于无损压缩数字音频的音频编码格式,由 Xiph.Org 基金会开发,[...]。通过 FLAC 算法压缩的数字音频通常可以减小到原始大小的 50% 到 70%,并解压缩为原始音频数据的相同副本。来源:维基百科
让我们添加文本参数
保存 python 文件并激活 venv,运行
您应该得到以下内容

在您的项目文件夹中,现在有一个audio.flac文件:您可以使用 VLC 媒体播放器播放它。
现在是时候创建 Streamlit 应用程序,为我们的项目提供漂亮的 UI。
5.使用Streamlit将所有内容整合在一起
您可以在我的专用 GitHub 存储库中找到所有图像和音频文件以及最终代码。
在本节中,我将简要解释代码以及如何运行它。
Streamlit是一个用于构建数据 Web 应用程序的库,无需了解任何前端技术(例如 HTML 和 CSS)。如果您想了解更多信息,请查看此处的清晰文档。1.24.0 版本包括专用于聊天界面的新小部件:与 LLM 一起使用非常有用(但不是在这里😁)
使用以下代码创建一个名为st-app.py的新文件:
您可能会注意到第一部分完全相同:这是我们需要这些函数并将它们链接到图形界面。我们唯一删除的是测试变量。
横幅图像位于我的存储库中:您可以在此处下载。
所有 Streamlit 应用程序都封装在 main() 函数中,我们将在最后使用光荣的指令调用该函数:
保存 python 文件并激活 venv,运行
您应该得到以下内容
Streamlit 应用程序运行
结论
我希望这篇文章对您有所帮助。发现开源语言模型的力量是令人惊奇的:为什么不学习如何在不运行现有商业软件的情况下自己执行所有人工智能任务呢?
Hugging Face 上的无 AI 法学硕士可以执行我们需要的所有任务:这取决于我们的创造力和技能,将它们连接在一起,创造出新的、令人惊叹的东西!
您可以在我的 GitHub 存储库中找到完整代码
作者:法比奥·马特里卡迪
- 作者:Inevitable AI
- 链接:https://www.Inevitableai.ltd/article/share71
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。