
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄
我们可以用 Hugging Face 模型和 python 做什么来理解长文本中的主要思想。抽象总结是关键!

在之前的文章中,我试图强调 AI 摘要的效率和效果。如果您是一名学生或者您必须阅读大量文档,您需要找到您的时间优化策略。
在本文中,我将向您展示如何使用 Python 和免费的 Hugging Face LLM 来理解我们想要研究的文本的含义。
总结的局限性
摘要文本是一种无需长时间阅读即可快速获取有用信息的有用方法。然而,NLP 摘要已被证明在有限的几个领域是有效的,至少目前是这样。
文本摘要是从包含事实数据的冗长文档中提取关键信息的有效方法。自然语言处理 (NLP) 模型可以将长文本概括为更短、更简单的句子。此类文件可能包括新闻文章、资料单和邮件。
但是,当您阅读每句话都建立在前一句话之上的文本时会发生什么?在这些情况下,文本摘要效果不佳。研究期刊和医学文本是总结无法给您带来良好结果的示例。同样的原则也适用于小说:摘要可能工作得很好,但它可能会错过作者试图表达的文本的风格和语气。

总结策略
文本摘要是一种 NLP 技术,可以在不改变文本含义的情况下减少文本长度。
提取和抽象技术是用于从原始文本数据中提取信息并创建摘要模型的两种主要策略。
提取方法选择文本中最重要的句子(不一定理解含义),因此结果摘要只是全文的一个子集。
相反,抽象模型使用高级 NLP(如句子和词嵌入)来理解文本的语义并生成有意义的摘要。因此,抽象技术更难从头开始训练,因为它们需要大量参数和数据。
总结的两种类型
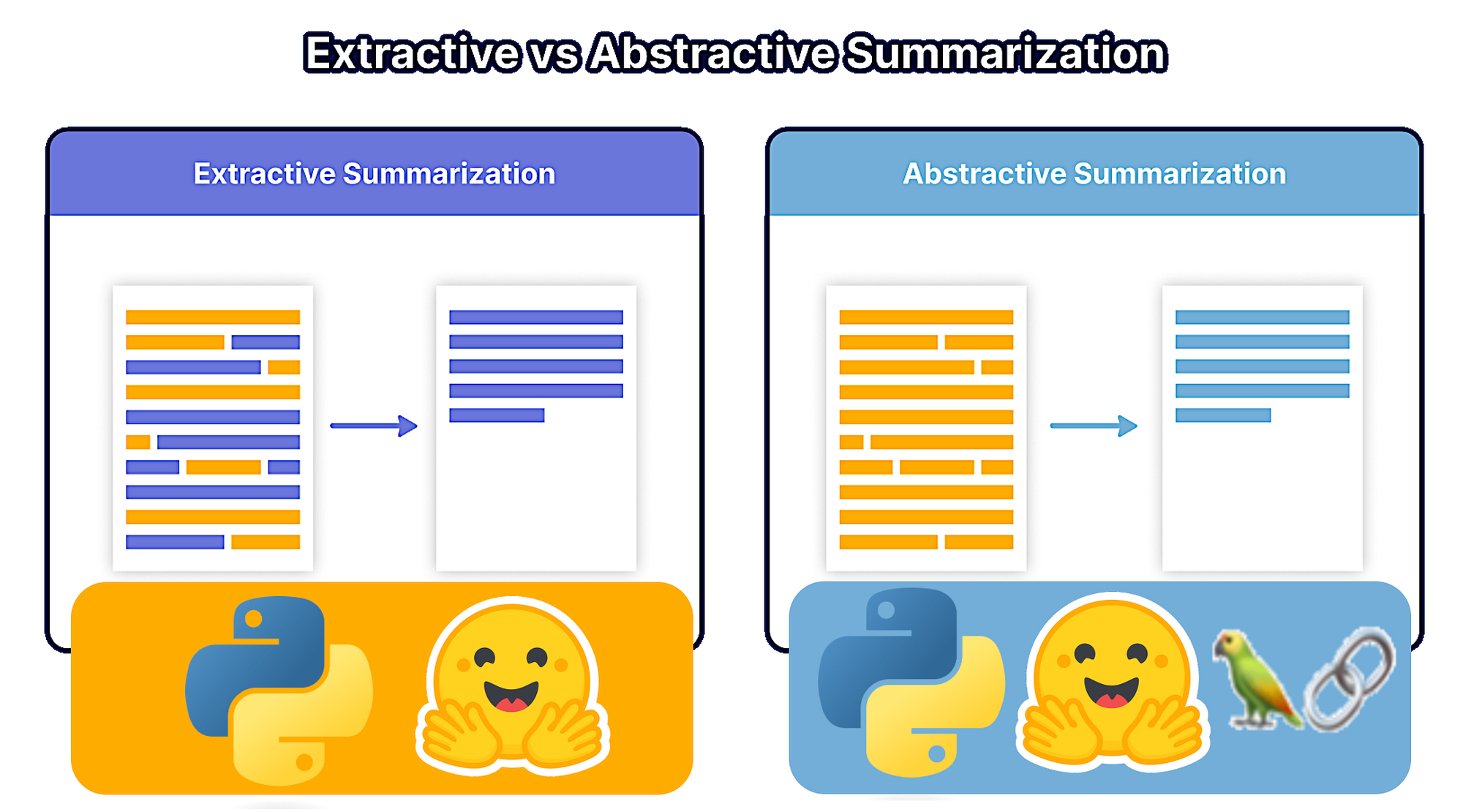
基本上有两种主要类型的文本摘要:提取式和抽象式
提取式
提取式摘要从文本中提取关键句子,按相关性和重要性对它们进行排序,并呈现最重要的句子。
这种方法不会创建新的单词或短语,它只是突出显示给定文本中的现有单词和短语。这就像拿一页文本并突出显示最重要的句子。
提取方法选择文本中最重要的句子(不一定理解含义),因此结果摘要只是全文的一个子集。
抽象式
抽象摘要试图猜测文本的含义并将其浓缩为简洁的摘要。
抽象模型利用词嵌入等自然语言处理 (NLP) 技术来理解文本的含义并创建有效的摘要。
它创建单词和短语,并以有意义的方式将它们组合在一起。它还尝试添加在文本中发现的最重要的事实。由于这些原因,抽象摘要技术比提取摘要技术更复杂且计算成本更高:它们更难从头开始训练,因为它们需要大量参数和数据。
让我们在免费的 Google Colab 笔记本(不需要 CPU)中深入研究 python 代码,以探索上述方法。
准备库和导入
您也可以在本地环境中遵循代码:我们将使用可以在任何现代 CPU 上运行的 LaMini 模型。
上述库是与 Torch 权重模型交互的核心。我们还将安装用于与 LangChain 进行文本和文档交互的库。
如果您现在在 Google Colab 中,则必须重新启动运行时:如果您在本地计算机上,则没有问题。
在 Notebook 上,您会注意到本地目录中有 2 个用于下载 LaMini-Flan-T5–248M 的单元格:如果您在计算机上进行本地安装,请记住在名为的子目录中下载相同的文件模型。
我们在这里下载一些 TXT 文件用于总结测试(您可以将它们用于您的实验)。
最终导入是这样的
使用 python 和 Hugging Face 进行提取摘要
提取式摘要需要很少的计算资源:这主要是因为我们从 transformers 库中有一个专用的管道。如果有管道,也意味着模型已经针对该特定任务进行了训练。
在这里,我们定义了一个函数(我将详细解释......),它接受一个检查点(对于本地模型)、要总结的文本、我们想要分割文本的块数(对于长文本......)和重叠(我们想在下一个块中带来上一个块中的多少个字符)。请记住RecursiveCharacterTextSplitter计算字符数,而不是单词数!
此处的 Tokenizer 和 Base_models 是使用 T5 转换器方法实例化的:如果您想使用其他模型(不是来自 T5 系列),请将 2 条指令替换为:
最后,我们遍历块并加入其中任何一个的摘要。
笔记!我们只使用带有result[0]['summary_text']的摘要文本。
为了测试我们的管道,我们使用了文章 BERT 的一小部分。
然后我们使用doc3变量调用汇总函数。
结果是一个内容丰富且做得很好的摘要……
如果我们使用差异发现工具(或抄袭工具……)检查摘要文本……那么我们得到了我们所期望的!

如您所见,几乎 80% 的摘要都是来自原文的文本:结果摘要只是全文的一个子集。
用python、Hugging Face和LangChain进行抽象总结
Abstractive Summarization 占用更多计算资源的原因是因为它使用了 text2text-generation 任务。理论上我们可以使用 text2text-generation 管道,给出一个提示指令来总结块并得到结果。
为了使流程自动化,我们将使用LangChain,特别是 Summarization Chain。
注意:此链有 3 种方法(stuff、refine、map_reduce),将包含在汇总函数中供您选择
Stuff是最简单的方法,它只对 LLM 进行一次调用。生成文本时,LLM 可以一次访问所有数据。这种方法的主要缺点是它只适用于较小的数据块。一旦处理大量数据,这种方法就不再可行。
Map Reduce可以扩展到比
StuffDocumentsChain. 对单个块上的 LLM 的调用是独立的。需要对 LLM 的调用比StuffDocumentsChain. 在最后的联合通话中丢失了一些信息。Refine:此方法涉及对第一块数据运行初始提示,生成一些输出。对于剩余的块,该输出与下一个块一起传入,要求 LLM 根据新块改进输出。可以引入更相关的上下文,并且可能比损失更小
MapReduceDocumentsChain。
我们的抽象摘要函数如下所示:
首先,它接受 5 个变量(上面的 4 个和方法,在“stuff”、“map_reduce”、“refine”之间进行选择)。
另一个主要区别是我们不需要迭代块:这个 Chain 已经接受来自RecursiveCharacterTextSplitter 的Document 对象。
最后,我们将 llm 实例化为 text2text-generation,并使用chain.run(docs)调用摘要链。
使用相同的 doc3 文本(文章 BERT 的一小部分:A Beginner-Friendly Explanation 由 Pushpam Punjabi 撰写)让我们看看结果……
首先要注意的是,它比来自管道的要短得多。第二个重点是文本本身。如果你在抄袭检查器或比较工具上运行它,你会发现两篇文章之间几乎看不到数学

结论
我希望这有助于提高我们的生产力并避免过度简化。
我的方法是通过提取摘要输入一个新主题或论点。只有在那之后我才开始阅读新的论文或文章,只有在阅读了摘要之后我才决定是否要阅读更多。
您可以在 GitHub 存储库中找到整个 Google Colab Notebook