
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄
这篇文章深入浅出地介绍了使用GPT的自治代理,从自主代理的定义、构成、工作流程、应用等方面进行详细阐述。作者清晰地解释了GPT-4等大型语言模型对于自主代理的驱动作用,并通过实例向读者展示了自主代理如何通过理解和创建信息、短期和长期记忆、规划和优先行动的推理技能、使用外部工具收集相关上下文和执行任务来完成长期目标。
每当我认为GPT的发展速度很快时,它变得更快了。在过去的一个月中,GPT/LLM支持的自主智能体的概念变得疯狂,其中最著名的项目AutoGPT在不到一个月的时间里获得了超过117K的GitHub星,得到了前所未有的社交媒体报道。许多其他项目,如BabyAGI、AgentGPT和斯坦福版的“Westworld”也经常被报道。这些代理具有高度的智能性,可以通过自己的思考和推理完成复杂的任务。
所有这些项目都建立在生成式自主代理的理念之上。你对像AutoGPT这样的自主代理如何在幕后工作感到好奇吗?你来对了地方——在本文中,我将提供一个全面的自主代理概述,包括它们是什么、它们如何工作、它们可以做什么、它们对企业和工人的影响,甚至提供一个构建简单自主代理的实践教程。阅读完本文后,你将对它们有更好的了解,并知道它们可能如何改变你周围的世界。

自主代理。使用稳定扩散创建的图像。
如果你不是技术人员,不知道如何编写代码,不要担心,我将用简单的语言解释这些概念。如果你准备好了,我们就开始吧!
自主代理是什么?
一些自主代理的例子包括AutoGPT、BabyAGI和斯坦福的交互式模拟。AutoGPT使用GPT-4作为底层思考引擎,自主完成用户设置的一组目标。一旦目标设定好了,它就会分解任务、计划行动、在线收集信息或使用外部工具,并迭代地重新评估和调整行动,直到达成目标[11]。BabyAGI是一个类似的但更小的项目,试图完成类似的过程,以帮助用户实现他们的目标[12]。
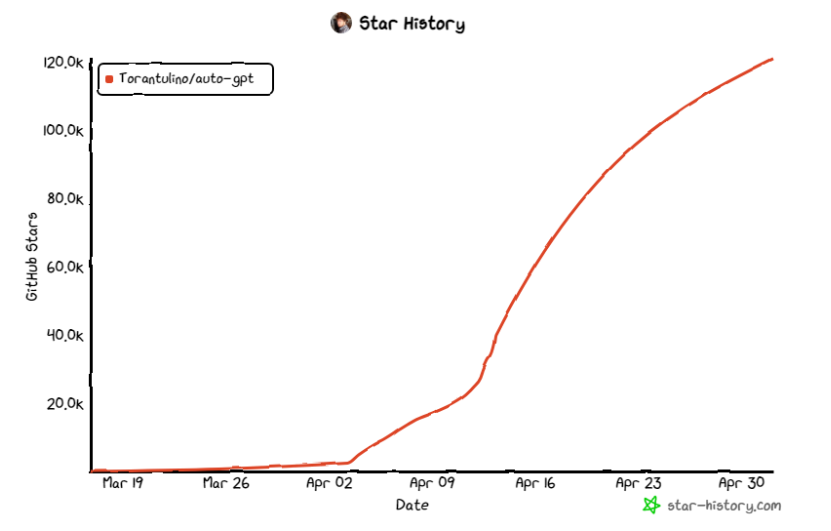
AutoGPT的星级历史。来自https://github.com/Significant-Gravitas/Auto-GPT[11]
斯坦福的交互式模拟是一个类似于“Westworld”的模拟游戏,其中所有NPC都由GPT控制,拥有自己的日常例行程序、任务、记忆等[13]。虽然这些只是自主代理的早期尝试,并且有许多限制,但它们展示了自主代理可以做到的巨大潜力。
那么它们实际上是如何工作的呢?让我们退后一步,看看GPT,即生成式预训练变压器,它是这些代理的驱动引擎。GPT是一个大型语言模型(LLM),它从大量的文本中学习,并可以基于输入序列(即提示)生成文本[1]。它是ChatGPT和自主代理的基础AI模型。
(要了解有关ChatGPT和GPT的更多信息,可以阅读:https://medium.com/design-bootcamp/how-chatgpt-really-works-explained-for-non-technical-people-71efb078a5c9)
在ChatGPT中,你可以给模型指示,它会按照你的指示执行。这种指示遵循行为已经很惊人了,并为人们提供了生产力提升。人们正在使用它进行研究、编写内容、编写代码等。但是有一个问题——该模型不会自动执行,它为你的一个输入提示提供一个单一的响应。你必须不断提供更多的上下文和输入来引导它完成更复杂的任务。
但是研究人员发现,这些模型实际上可以做的比生成文本更多——大型语言模型可以具有推理能力。这在早期的提示工程研究中是明显的。例如,小岛等人发现,在提示的末尾添加“让我们一步一步地思考”可以大大提高GPT的性能[2],魏等人发现,思维链提示可以“引导大型语言模型推理”[3]。
(还有许多其他的提示工程技术,试图引出LLM的更好性能,你可以阅读更多信息在这里)
这种新出现的能力是自主代理的关键。如果大型语言模型可以推理和思考,它们可能会计划任务并使用工具完成更复杂的任务。研究人员和工程师开始探索是否可以创建自主代理——具有基于用户输入和访问一套工具来做出决策的能力的AI动力智能系统。
仅具有推理技能还不足以完成需要比大型语言模型知道更多信息的复杂任务。研究人员开发了像LangChain[4]和Semantic Kernel[5]这样的框架,使LLM更容易使用外部工具,编排其他AI模型,调用API,并在向量数据库中存储信息。许多项目,包括Toolformer[6]、JARVIS(HuggingGPT)[7]、VisualChatGPT(TaskMatrix)[8]等,成功地允许LLM使用各种外部工具。
他们还试图教语言模型如何更好地使用外部工具并从错误中学习。姚等人提出的ReAct(Reasoning-Acting)框架介绍了一个交错的思考和行动提示的想法,以提高与外部API交互的性能[9]。Shinn等人提出了Reflexion,它使用动态内存和自我反思来增强其推理和行动能力,以完成任务[10]。
通过这些各种研究和开源项目,自主代理现在可以尝试通过思考子任务、计划采取哪些行动、利用外部工具执行这些行动,并反思结果来实现一个长期目标。
自主代理如何工作?
从上一节中,我们已经知道自主代理可以通过自己的基本语言技能来完成长期目标,这是由以下技能支持的:理解和创建信息的基本语言技能,短期和长期记忆,规划和优先行动的推理技能,以及使用外部工具收集相关上下文和执行任务。
在这一节中,我们将详细介绍整个过程,并解释每个主要组件的工作原理。自主代理的典型结构和过程如下:
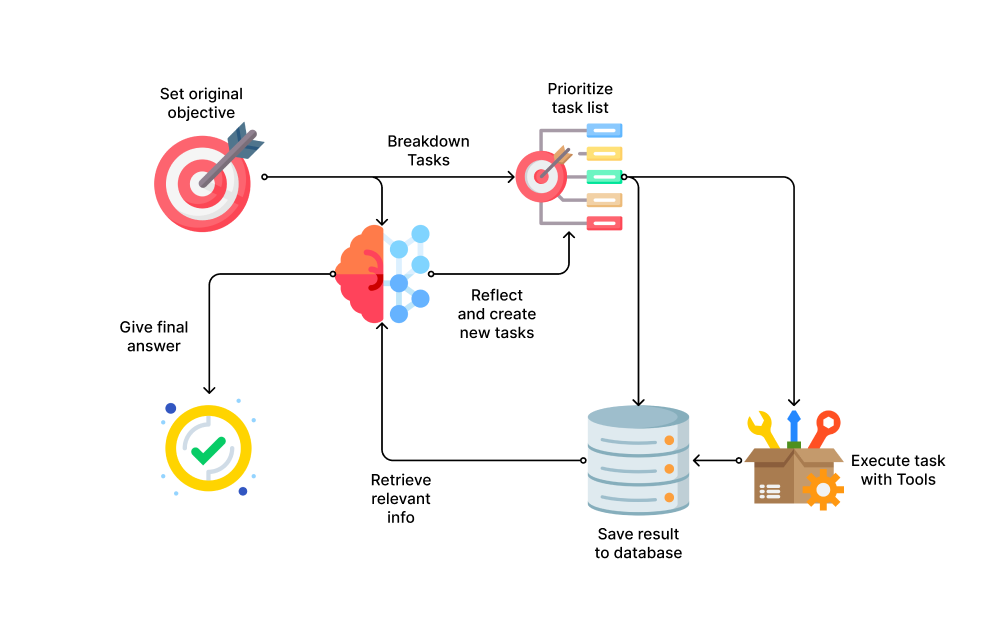
自主代理的典型过程。
1)设定目标:用户将设定一个自主代理将完成的高级目标。例如,“构建一个心理健康日记应用程序。”
2)分解任务:代理将使用LLMs(如GPT-4)将目标分解为一个要做的潜在任务列表。任务可以是信息收集,如“在Google上搜索心理健康日记应用程序竞争对手”,也可以是执行,如“为记录用户心情的Web应用程序页面编写JavaScript代码”。这个任务列表存储在长期记忆中,通常是一个向量数据库。
3)优先级。一旦有任务列表,代理就会使用LLMs的推理技能来评估和优先考虑任务,以决定下一个执行的任务。
4)执行。代理将执行任务,如果不需要外部信息或工具,它将自己执行,否则将使用外部工具收集相关信息以完成任务。执行的结果和收集的信息也将保存在长期记忆中。
5)评估和创建新任务。当代理完成一个任务时,它将评估手头剩余的任务和先前执行的结果,仍然使用LLMs的推理能力。然后,它将提出新的需要完成的任务,以实现最终目标。
6)重复。将重复步骤2-5,直到代理认为已经完成了最初的目标,或者用户干预为止。
不同实现项目的确切流程可能有所不同,但总体流程是相似的。您可以注意到,以下组件是促进自主代理流程所必需的。
LLM是链接流程每个步骤的推理引擎。它们将一个更大的目标分解为较小的任务(步骤2),将任务设置为优先级(步骤3),将决定它们是否需要更多信息或使用工具(步骤4),并将评估执行结果以获取更新的任务列表(步骤5)。为确保这些推理步骤得到有效和正确的完成,我们可以使用提示工程来将提示复杂化。在下一节中,我们将提供可以执行所有这些任务的提示示例。
数据库保留LLM的上下文和内存。由于对LLM(或GPT API)的每个调用都限制为单个对话,因此为了向LLM提供它不知道的信息,我们需要动态地从外部存储和检索信息。许多这些自主代理使用矢量数据库,例如Pinecone [14]、Weaviate [15]或Chroma,以实现其高效的文本搜索功能。代理可以将其目标、任务列表和从Web搜索中收集的信息或从先前步骤的执行结果保存到这些矢量数据库中。
外部工具允许LLM与外部世界交互。虽然LLM在文本生成方面很强大,但它们不能自行与文本框之外的外部世界进行交互。因此,我们需要工具,它们可以用来收集信息并与外部世界进行交互。这些工具包括浏览器、代码解释器和其他AI模型,以处理文本以外的模态信息等。
亲自构建一个简单的自主代理
在前面的部分中,我们已经涵盖了自主代理是什么、它们如何获得它们的功能以及自主代理内的典型流程。但是,对于某些人来说,纯理论可能会显得抽象,因此让我们建立一个简单的自主代理,其中包含了我们所描述的内容。
在本节中,我们将逐步构建一个最简单的自主代理。这个自主代理可以在Arxiv中搜索相关论文,并根据用户的研究问题总结论文的核心思想。我们将分别构建它:在第一个示例中,我们将使用LangChain来构建代理,它将许多低层次的细节抽象化,但更容易实现;在第二个示例中,我们将从头开始构建一个最简单的代理。
该部分的Colab笔记本可在以下位置找到:https://github.com/Troyanovsky/autonomous_agent_tutorial
使用LangChain构建自主代理
第一个示例是使用LangChain的高级示例。LangChain是一个Python框架,将许多LLM的功能包装成易于使用的函数和方法。我们可以使用代理模块和arxiv工具快速构建一个自主代理。
安装软件包,设置环境并导入必要的软件包。
我们首先定义语言模型可以使用的工具:arxiv api,包括工具的名称和描述,以便LLM知道它可以在需要时使用工具。
然后,我们可以通过将定义的工具和LLM传递给代理来初始化代理。该代理将通过其名称和描述识别工具,并决定是否需要使用该工具。
然后,我们可以使用问题运行代理:
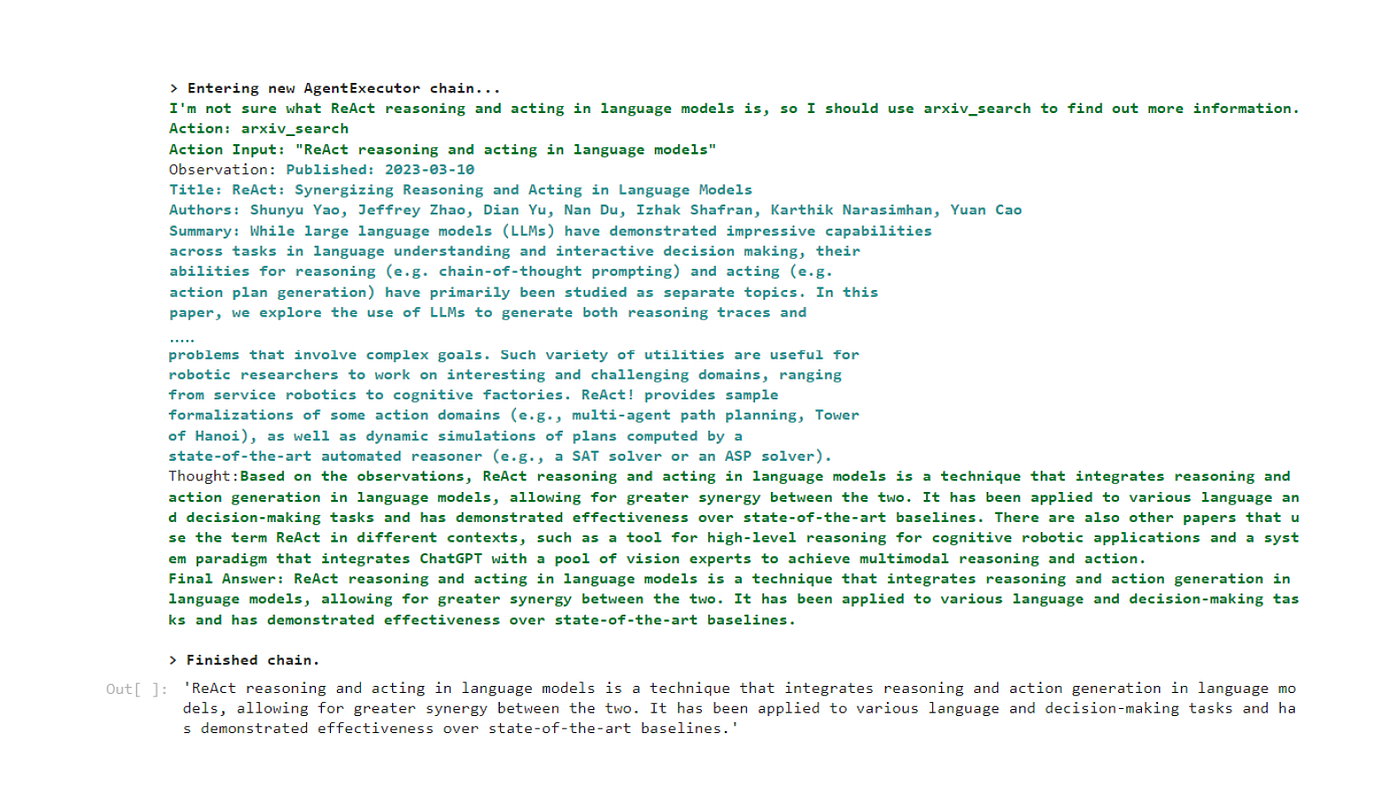
代理的思考和执行过程输出。
我们可以看到,代理首先思考任务,发现它没有所有必要的信息,因此创建一个动作以使用arxiv API搜索相关论文。然后它执行此操作并返回了三篇论文,然后可以使用这些论文回应用户的请求。
从头开始构建自主代理
如果您想深入了解自主代理的工作原理,我将向您展示一个最简单的自主代理实现,它与第一个示例完成的任务相同,但这次我们将不使用LangChain进行实现。
安装软件包,设置环境并导入必要的软件包。
将OpenAI API调用封装在一个函数中,以便于使用。
将Arxiv API封装在一个函数中,以便将其提供给GPT代理在需要时使用。
使用GPT确定要采取的动作,通过给定的目标、内存和工具。如果它认为已完成目标,只需给出答案。如果它需要更多信息,它将选择工具以获取相关信息,基于工具描述。(这是上一节中自主代理工作过程的步骤2和3的简化版本。)
解析GPT的响应以确定目标是否完成。如果已完成,则只需给出最终答案。如果目标无法在上下文和工具中完成,它将通过说它无法回答请求来完成工作。如果GPT选择工具,请执行工具并保存工具结果在内存中。
如果GPT选择了工具,则使用它选择的参数执行工具。此函数返回执行结果,以便GPT可以获得相关信息。
使用内存和可用工具初始化自主GPT代理。它将询问用户目标并自主运行,直到完成目标。(作为安全措施,它还会在5次迭代后停止,以防万一出现问题。)

第二个代理的输出。带有思考,工具结果的观察以及最终答案。
自主代理为什么很重要
这些项目之所以获得如此多的公众关注和媒体曝光,不仅因为它们看起来很酷,而是它们展示了改变我们日常生活和工作的潜力。它们可以成为企业和工人的一个重大机遇,并且可以成为我们个人生活中的强大助手。
对于企业而言,这些自主代理可以提供成本节约,并允许公司在较少的人力资源下更有生产力。在未来,企业家可以通过这些AI自主代理完成大部分重复性工作,只需少数关键决策者即可创立有利可图的业务。如果他们知道如何利用这些代理,小团队将拥有更多的杠杆作用。还可能会有另一种商业模式,即为其他公司提供量身定制的代理。如果一家公司拥有深入的行业知识,它可以更好地设计代理以更高效地完成任务。他们还可以设计和销售这些代理可以使用的工具。未来可能会有以代理为中心的产品(或许ChatGPT插件已经是代理为中心的产品的早期形式?)
对于工人而言,这些自主代理可以释放出大量时间,让他们专注于需要人类因素的更重要的任务,例如情感同情,创造性问题解决和批判性思维。从我的个人经验来看,即使是现在不那么聪明的自主代理,我也可以在我的产品管理工作流程中节省一些时间。(只是不要过于依赖代理,因为它们有时也会犯错。)
在我们的个人生活中,这些代理也可以成为比旧语音助手Siri更有帮助的助手。想象一下,在未来,您只需要将一些任务添加到待办事项列表中,您的自主代理就会完成它们——订购杂货,预订餐厅,甚至安排家庭维修。他们还可以通过分析您的可穿戴设备的健康数据来帮助您监测和规划锻炼、营养和心理健康。
最后的话
我希望本文为您提供了一个全面而易于理解的带有LLM的自主代理概述。作为快速回顾,以下是本文涉及的一些主要点:
1)自主代理是由像GPT这样的LLM驱动的智能系统,可以在最少的人类指导下实现长期目标。
2)它们的能力包括基本语言能力、紧急推理能力、使用外部工具的能力和访问向量数据库的能力。
3)自主代理的典型过程是:从用户那里获得目标、拆分任务、优先任务、执行任务(使用外部工具)、评估结果和创建新任务。
4)自主代理可能会通过减少企业成本并提高工人生产力而改变商业格局。
由于这项技术仍处于初级阶段,还有很多需要探索和了解。我相信,在早期采用这些代理或使用它们的人中,将会有一段时间他们会比那些拒绝了解它们的人更具竞争力。
作者:Guodong(Troy)Zhao
- 作者:Inevitable AI
- 链接:https://www.Inevitableai.ltd/article/share28
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。