
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄
使用 Streamlit 和 MLflow 制作垃圾邮件过滤器,提升您的 MLOps 之旅

为什么要开始这项工作❓
想象一下:您有了一个全新的商业想法,并且您所需的数据就在您的指尖。你们都兴奋地投入到创建这个奇妙的机器学习模型🤖。但是,说实话,这段旅程绝非易事!你将疯狂地进行实验,处理数据预处理、选择算法和调整超参数,直到你头晕目眩 😵💫。随着项目变得越来越棘手,就像试图捕捉烟雾一样——你会忘记一路上所有的疯狂实验和绝妙想法。
但是等等,还有更多!一旦您获得了该模型,您就必须像冠军一样部署它!随着数据和客户需求的不断变化,您重新训练模型的次数将比换袜子的次数还多!这就像永无止境的过山车,您需要一个坚如磐石的解决方案来将其保持在一起🔗。输入 MLOps!这是给混乱带来秩序的秘密武器 ⚡
好吧,伙计们,既然我们已经了解了为什么,那么让我们深入了解本博客中的内容和有趣的方法。
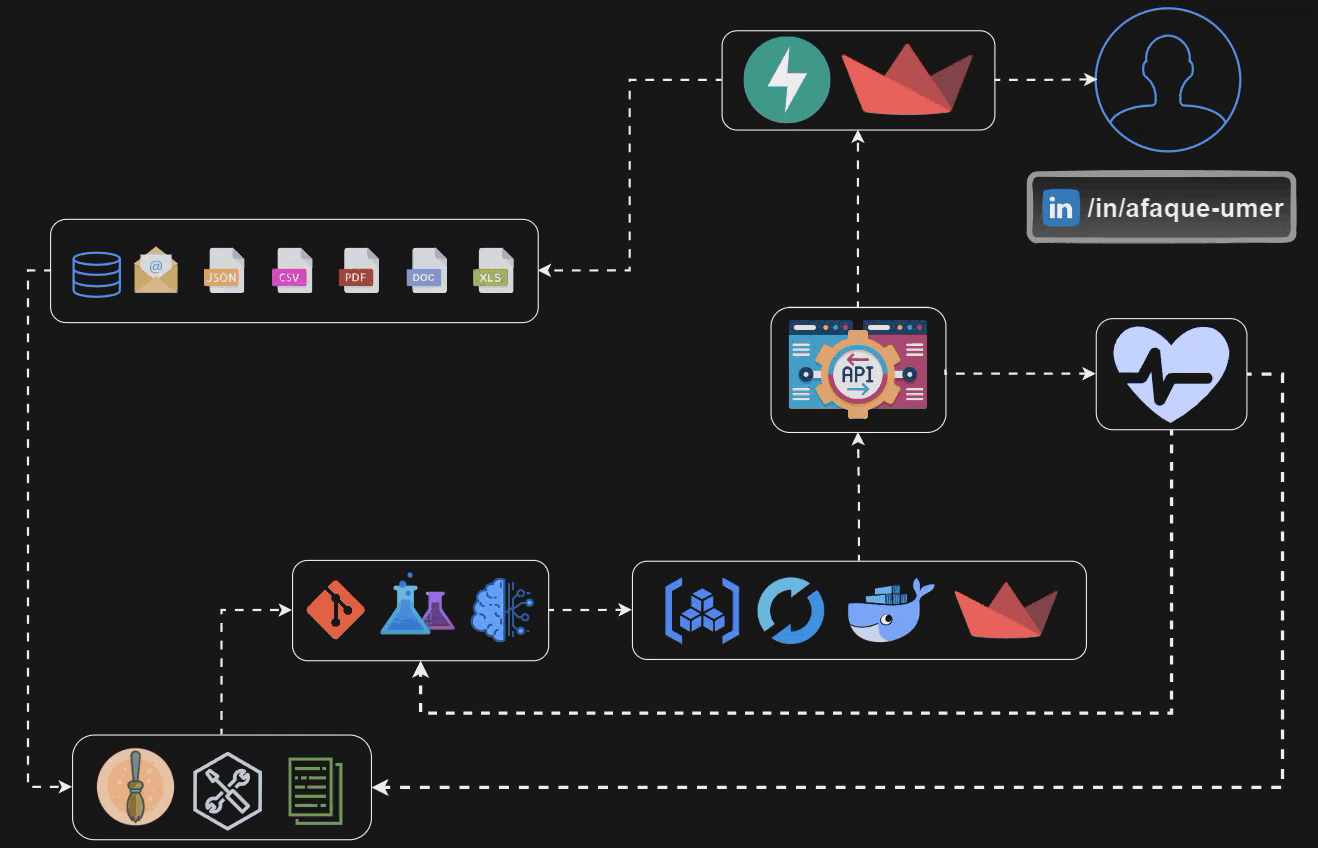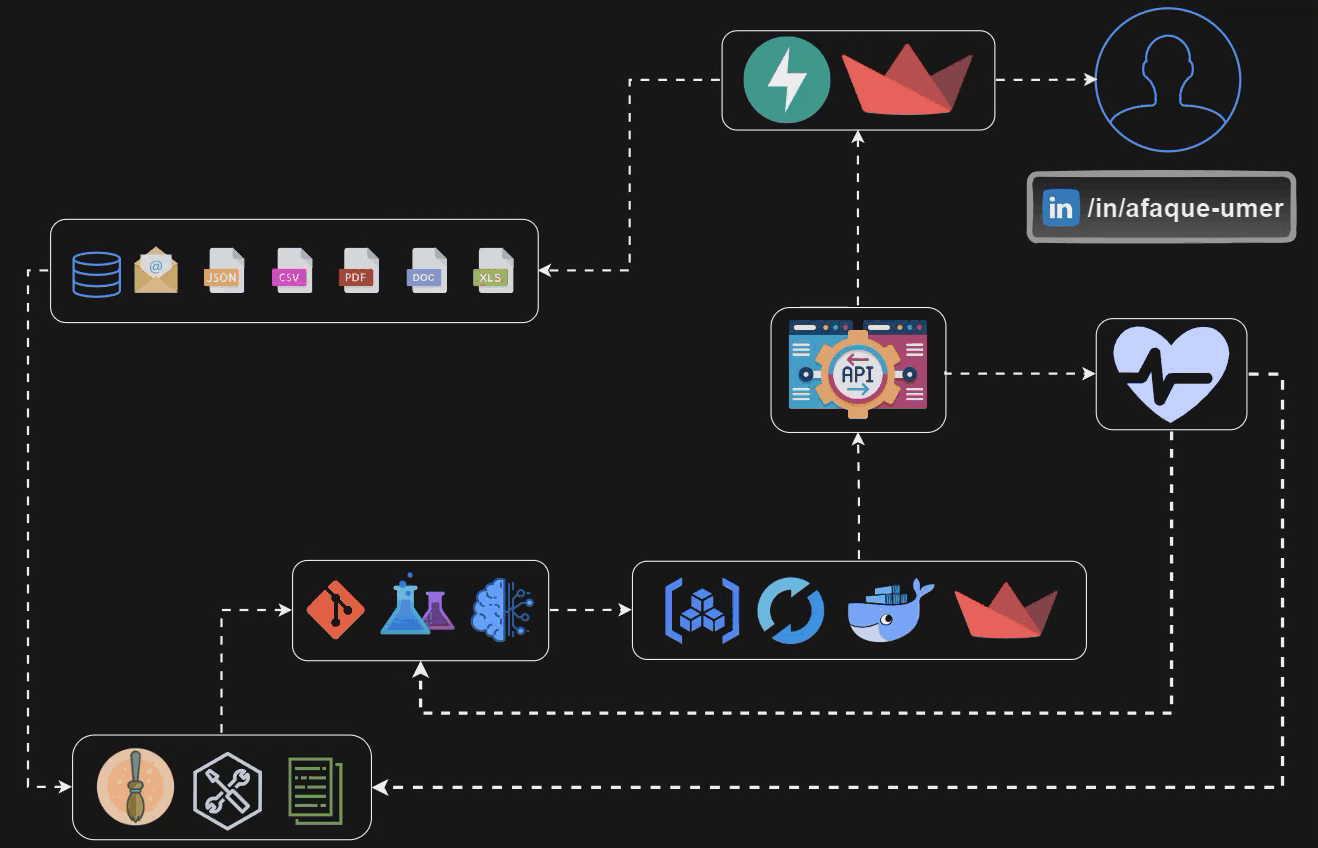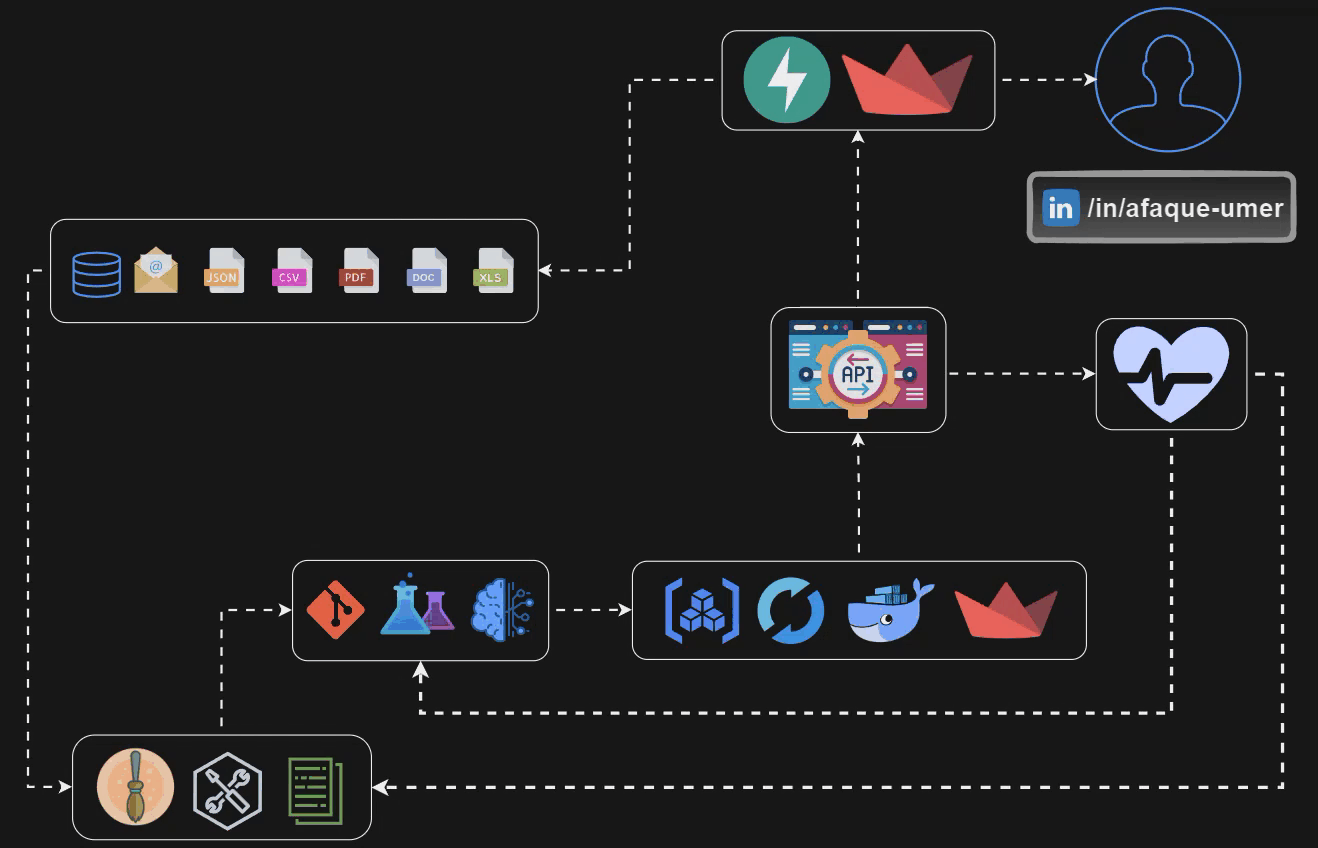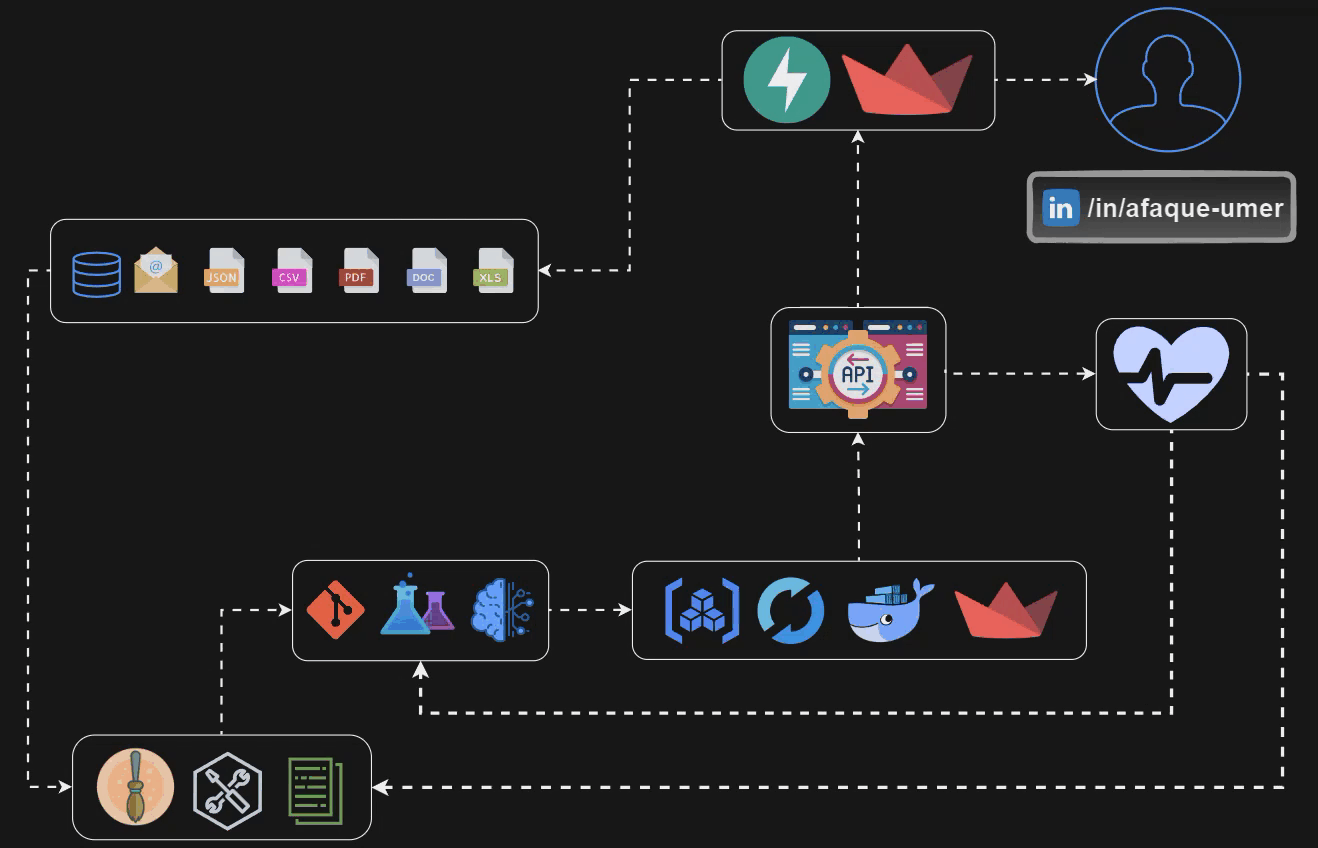
让我们看一下我们将在本文结束时构建的数据流👆
坚持住,因为这不会是一个快速阅读!因为压缩它意味着错过重要的细节。我们正在制定一个端到端 MLOps 解决方案,为了保持真实性,我必须将其分为三个部分,但是,由于某些出版指南,我必须将其分为一系列 2 篇博客文章。
第 1 部分:我们将奠定基础和理论 📜第 2 部分:现在就是行动的地方了!我们正在构建一个垃圾邮件过滤器并使用 MLflow 跟踪所有这些疯狂的实验 🥼🧪第 3 部分:我们将专注于真正的交易 - 部署和监控我们的冠军模型,使其做好生产准备 🚀
让我们与 MLOps 一起摇滚吧!
第 1 部分:要点 🌱
什么是 MLOps ❔
MLOps 代表了一系列方法论和行业最佳实践,旨在帮助数据科学家在大规模生产环境中简化和自动化整个模型训练、部署和管理生命周期。
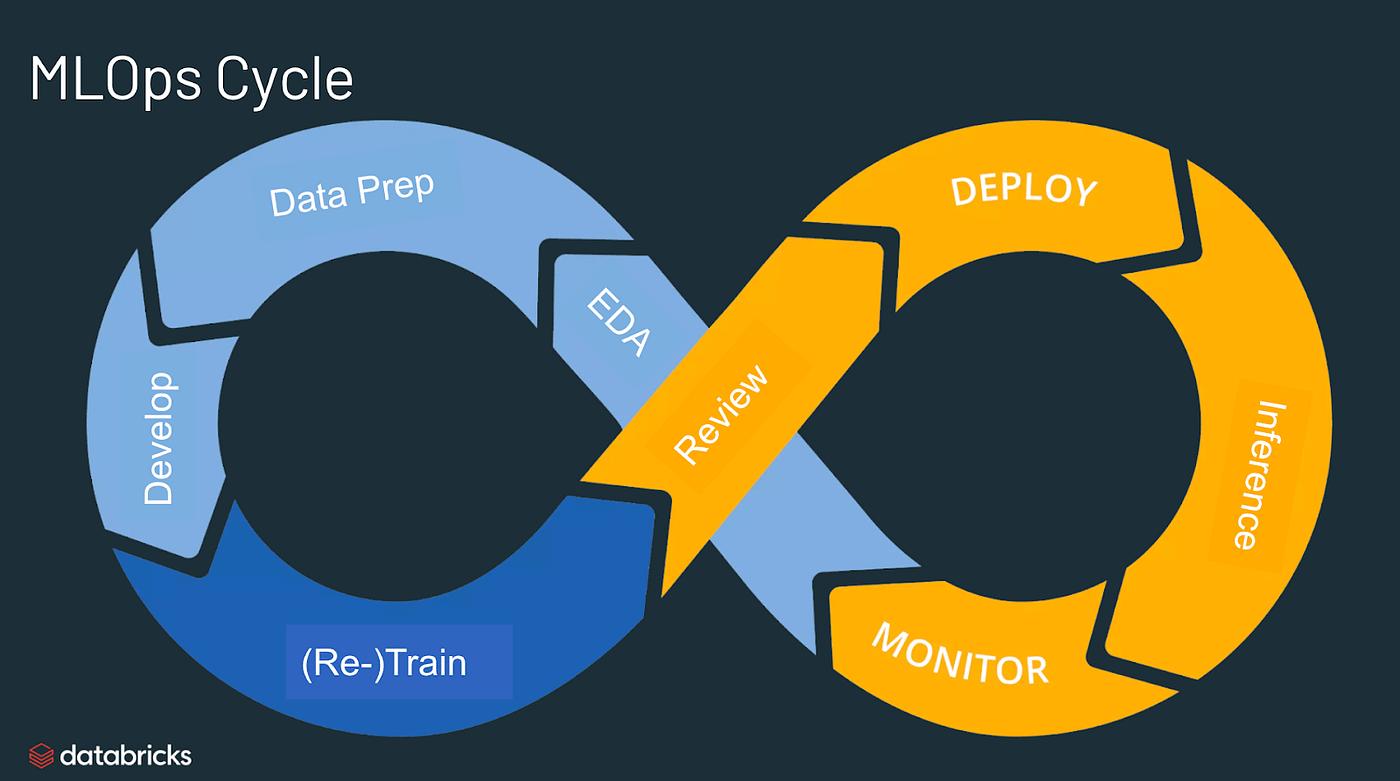
它逐渐成为管理整个机器学习生命周期的独特且独立的方法。MLOps 过程的基本阶段包括以下几个:
1)数据收集:
从不同来源收集相关数据进行分析。
2)数据分析:
探索和检查收集的数据以获得见解。
3)数据转换/准备:
清理、转换和准备模型训练的数据。
4)模型训练和开发:
使用准备好的数据设计和开发机器学习模型。
5)模型验证:
评估模型的性能并确保其准确性。
6)模型服务:
部署经过训练的模型来服务于现实世界的预测。
7)模型监控:
持续监控模型在生产中的性能以保持其有效性。
8)模型重新训练:
定期使用新数据重新训练模型,以保持模型最新且准确。
我们将如何实施它?虽然有多个选项可用,例如 Neptune、Comet 和 Kubeflow 等,但我们将坚持使用 MLflow。那么,让我们熟悉 MLflow 并深入了解其原理。
MLflow 101
MLflow 就像机器学习的瑞士军刀 - 它具有超级通用性和开源性,可帮助您像老板一样管理整个 ML 旅程。它可以与所有大型 ML 库(TensorFlow、PyTorch、Scikit-learn、spaCy、Fastai、Statsmodels 等)配合良好。不过,您也可以将它与您喜欢的任何其他库、算法或部署工具一起使用。另外,它的设计是超级可定制的——您可以使用自定义插件轻松添加新的工作流程、库和工具。

机器学习工作流程:MLflow
MLflow 遵循模块化和基于 API 的设计理念,将其功能分为四个不同的部分。

现在,让我们一一查看这些部分!
MLflow Tracking: 它是一个 API 和 UI,允许您在机器学习运行期间记录参数、代码版本、指标和工件,并在以后可视化结果。它适用于任何环境,使您能够登录到本地文件或服务器并比较多次运行。团队还可以利用它来比较不同用户的结果。
Mlflow Projects:这是一种轻松打包和重用数据科学代码的方法。每个项目都是一个包含代码或 Git 存储库的目录以及一个用于指定依赖项和执行指令的描述符文件。当您使用跟踪 API 时,MLflow 会自动跟踪项目版本和参数,从而可以轻松地从 GitHub 或 Git 存储库运行项目并将其链接到多步骤工作流程中。
Mlflow Models:它使您能够打包不同风格的机器学习模型,并提供各种部署工具。每个模型都保存为一个目录,其中包含一个列出其支持的风格的描述符文件。MLflow 提供了将常见模型类型部署到各种平台的工具,包括基于 Docker 的 REST 服务器、Azure ML、AWS SageMaker 以及用于批处理和流式推理的 Apache Spark。当您使用跟踪 API 输出 MLflow 模型时,MLflow 会自动跟踪它们的来源,包括它们来自的项目和运行。
Mlflow Registry: 它是一个具有 API 和 UI 的集中式模型存储,可协作管理 MLflow 模型的整个生命周期。它包括模型沿袭、版本控制、阶段转换和有效模型管理的注释。
这就是我们对 MLflow 产品的基本了解。有关更深入的详细信息,请参阅此处的官方文档👉📄(https://www.mlflow.org/docs/latest/index.html)。现在,有了这些知识,让我们深入了解第 2 部分。我们将通过创建一个简单的垃圾邮件过滤器应用程序开始,然后我们将进入全面的实验模式,通过独特的运行跟踪不同的实验!
第 2 部分:实验🧪和观察🔍
好了,朋友们,准备好开始激动人心的旅程吧!在我们深入实验室进行实验之前,让我们先制定一下我们的计划,以便我们知道我们正在构建什么。
首先,我们将使用随机森林分类器来构建垃圾邮件分类器(我知道多项式 NB 对于文档分类效果更好,但是,我们想使用随机森林的超参数)。一开始我们会故意让它变得不太好,只是为了获得刺激。
然后,我们将释放我们的创造力并跟踪各种运行,调整超参数并尝试使用 Bag of Words 和 Tfidf 等很酷的东西。你猜怎么着?我们将像老板一样使用 MLflow UI 来完成所有甜蜜的跟踪操作,并为下一部分做好准备。所以系好安全带,因为我们会玩得很开心!🧪💥
与数据合而为一🗃️
对于此任务,我们将使用 Kaggle 上提供的垃圾邮件收集数据集。该数据集包含 5,574 条英文 SMS 消息,标记为 ham(合法)或垃圾邮件。然而,数据集存在不平衡,大约有 4,825 个火腿标签。为了避免偏差并保持简洁,我决定删除一些火腿样本,将其减少到 3,000 个左右,并保存生成的 CSV 以便在我们的模型和文本预处理中进一步使用。请根据您的需求随意选择您的方法 - 这只是为了简洁起见。这是显示我如何实现这一目标的代码片段。
构建基本的垃圾邮件分类器🤖
现在我们已经准备好了数据,让我们快速构建一个基本的分类器。不、可以用计算机无法掌握文本语言的陈词滥调来对话,因此需要对其进行矢量化以进行文本表示。完成后,我们可以将其输入 ML/DL 算法。
我们将加载数据,并对消息进行预处理以删除停用词、标点符号等。我们甚至会对它们进行词干化或词形还原以达到更好的效果。然后是令人兴奋的部分 - 对数据进行矢量化以获得一些令人惊奇的功能。接下来,我们将分割数据进行训练和测试,将其放入随机森林分类器中,并在测试集上做出有趣的预测。最后,是时候看看我们的模型表现如何了!⚡
在这段代码中,我提供了几个实验选项作为注释,例如带或不带停用词的预处理、词形还原、词干提取等。同样,对于矢量化,您可以在词袋、TF-IDF 或嵌入之间进行选择。现在,让我们进入有趣的部分!我们将通过顺序调用这些函数并传递超参数来训练我们的第一个模型。
是的,我完全同意,这个模型几乎没什么用。精度几乎为零,这导致 F1 分数也接近于 0。由于我们存在轻微的类别不平衡,因此 F1 分数变得比准确性更重要,因为它提供了精确度和召回率的总体衡量标准 - 这就是它的魔力!所以,这就是我们的第一个可怕的、荒谬的、无用的模型。但是,嘿,不用担心,这都是学习之旅的一部分🪜。
现在,让我们启动 MLflow 并准备好尝试不同的选项和超参数。一旦我们对事情进行微调,一切就会开始变得有意义。我们将能够像专业人士一样可视化和分析我们的进展!
MLflow 入门♾️
首先,让我们启动并运行 MLflow。为了保持整洁,建议设置虚拟环境。您可以简单地使用 pip 安装 MLflow 👉
pip install mlflow安装完成后,通过在终端中运行 👉 来启动 MLflow UI
mlflow ui(确保它位于安装 MLflow 的虚拟环境中)。这将在托管于http://localhost:5000 的本地浏览器上启动 MLflow 服务器。你会看到类似👇的页面
由于我们尚未记录任何内容,因此无需在 UI 上检查太多内容。MLflow 提供多种跟踪选项,例如本地、本地数据库、服务器甚至云端。对于这个项目,我们现在将坚持使用本地的一切。一旦我们掌握了本地设置的窍门,稍后就可以传递跟踪服务器 URI 并配置一些参数 - 基本原理保持不变。
现在,让我们深入了解有趣的部分 - 存储指标、参数,甚至模型、可视化或任何其他对象(也称为工件)。
MLflow 的跟踪功能可以被视为机器学习开发背景下传统日志记录的演变或替代。在传统日志记录中,您通常会使用自定义字符串格式来记录模型训练和评估期间的超参数、指标和其他相关详细信息等信息。这种记录方法可能会变得乏味且容易出错,尤其是在处理大量实验或复杂的机器学习管道时,而 Mlflow 可以自动记录和组织这些信息的过程,从而更容易管理和比较实验,从而提高效率和可重复的机器学习工作流程。
Mlflow Tracking 📈
Mlflow Tracking以三个主要功能为中心:
log_param用于记录参数、log_metric用于记录指标以及log_artifact用于记录工件(例如,模型文件或可视化)。这些功能有助于在机器学习开发过程中组织和标准化地跟踪实验相关数据。
记录单个参数时,会使用元组中的键值对进行记录。另一方面,当处理多个参数时,您将使用带有键值对的字典。同样的概念也适用于日志记录指标。这是一个代码片段来说明该过程。
了解实验 🧪 与运行 🏃♀️
实验充当代表一组相关机器学习运行的容器,为具有共享目标的运行提供逻辑分组。每个实验都有一个唯一的实验 ID,您可以指定一个用户友好的名称以便于识别。
另一方面,运行对应于实验中机器学习代码的执行。您可以在单个实验中使用不同的配置进行多次运行,并且每次运行都会分配一个唯一的运行 ID。跟踪信息(包括参数、指标和工件)存储在后端存储中,例如本地文件系统、数据库(例如 SQLite 或 MySQL)或远程云存储(例如 AWS S3 或 Azure Blob 存储) 。
MLflow 提供统一的 API 来记录和跟踪这些实验详细信息,无论使用哪个后端存储。这种简化的方法可以轻松检索和比较实验结果,从而提高机器学习开发过程的透明度和可管理性。
首先,您可以使用任一
mlflow.create_experiment()方法或更简单的方法创建实验mlflow.set_experiment("your_exp_name")。如果提供了名称,它将使用现有的实验;否则,将创建一个新的日志来记录运行。接下来,调用
mlflow.start_run()初始化当前活动运行并开始记录。记录必要的信息后,使用 关闭运行mlflow.end_run()。这是说明该过程的基本片段:
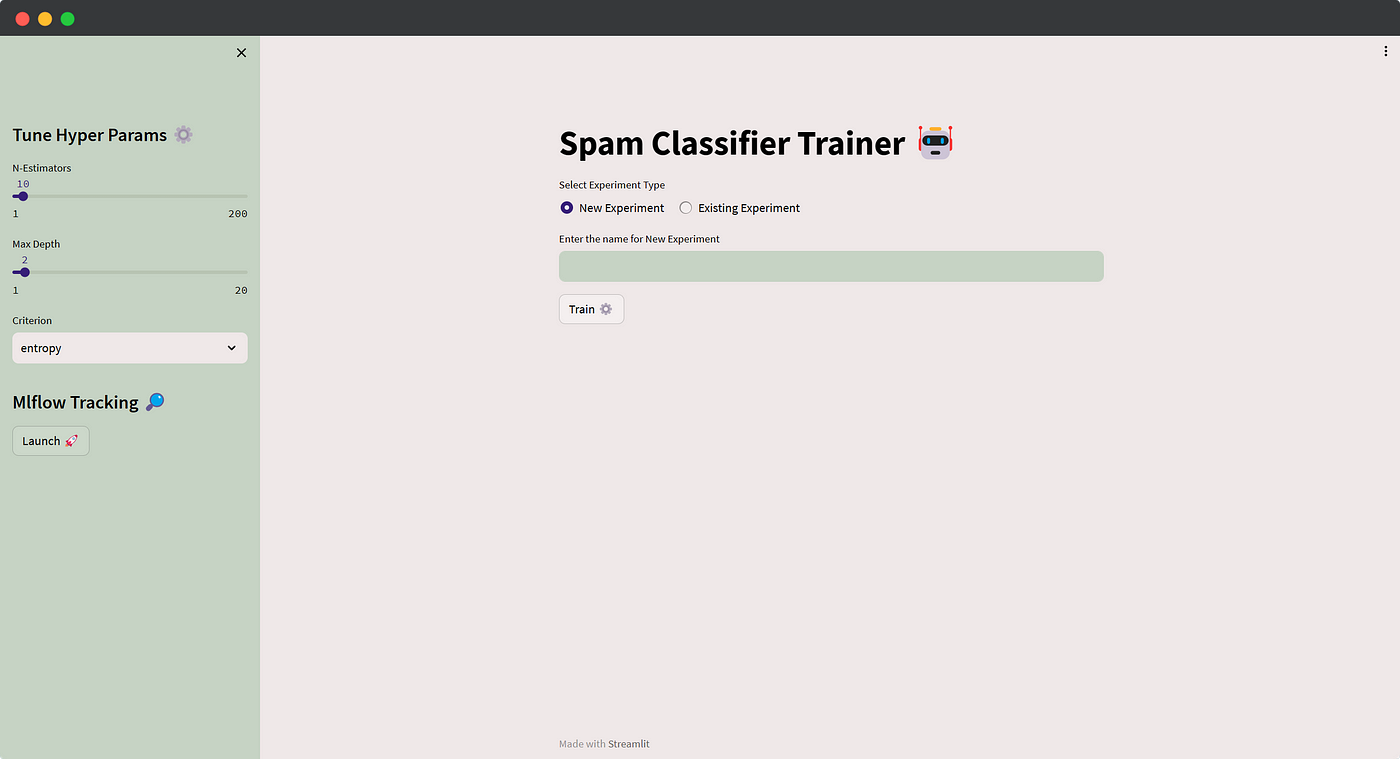
使用 Streamlit 创建用于超参数调整的 UI🔥
我们将选择一种用户友好的方法,而不是通过 shell 执行脚本并在那里提供参数。让我们构建一个基本的 UI,允许用户输入实验名称或特定的超参数值。单击训练按钮时,它将使用指定的输入调用训练函数。此外,我们将探讨在保存大量运行后如何查询实验和运行。
借助此交互式 UI,用户可以轻松尝试不同的配置并跟踪其运行情况,以实现更简化的机器学习开发。
我不会深入研究 Streamlit 的细节,因为代码很简单。我对早期的 MLflow 日志记录训练功能进行了细微调整,并实现了自定义主题设置。在运行实验之前,系统会提示用户选择输入新实验名称(记录在该实验中运行)或从下拉菜单中选择使用 生成的现有实验
mlflow.search_experiments()。此外,用户可以根据需要轻松微调超参数。这是应用程序的代码👇这是应用程序的样子 🚀
作者:Afaque Umer
- 作者:Inevitable AI
- 链接:https://www.Inevitableai.ltd/article/share126
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。