
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄
该版本包括三个模型:EnCodec、AudioGen 和 MusicGen。

音频正在迅速成为生成人工智能的新领域之一。为了生成高保真音频,Meta AI 面临着对不同尺度的复杂信号和模式进行建模的挑战。在各种音频类型中,音乐尤其令人畏惧,因为它融合了本地和远程模式,从单个音符到具有多种乐器的复杂音乐结构。虽然传统方法依赖于 MIDI 或钢琴卷帘等符号表示,但它们无法捕捉音乐固有的表现力细微差别和风格丰富性。Meta AI最近推出了 AudioCraft,这是一系列用于生成高质量音频的生成式 AI 模型。
AudioCraft 模型系列是一项值得注意的成就,展示了生成具有持久一致性的高质量音频的能力,并提供了用户友好的交互界面。与该领域的先前作品相比,AudioCraft 简化了音频生成模型的整体设计,为探索 Meta 多年来开发的最先进模型提供了一个全面的工具包。此外,它使用户能够突破界限并开发自己的定制模型。
AudioCraft 基于三个核心模型,即 MusicGen、AudioGen 和 EnCodec。AudioCraft 展示了其生成不同形式音频的多功能性。MusicGen 使用 Meta 拥有且专门授权的音乐进行训练,可将基于文本的用户输入转换为令人印象深刻的音乐作品。另一方面,AudioGen 经过公开的音效训练,可以巧妙地根据与环境声音和音效相关的文本提示生成音频,例如狗叫声、汽车喇叭声或木地板上的脚步声。
1) 音频生成:EnCodec
AudioCraft 模型需要解决从原始音频信号生成音频的复杂挑战,因为它涉及对极长序列进行建模。持续几分钟并以 44.1 kHz(音乐录音标准)采样的典型音乐曲目包含数百万个时间步长。相比之下,基于文本的生成模型(如 Llama 和 Llama 2)将文本处理为子词,每个样本仅代表几千个时间步。
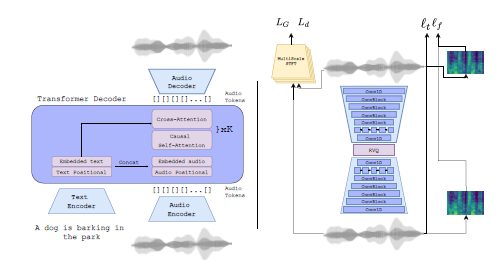
为了解决这种复杂性,Meta AI 采用 EnCodec 神经音频编解码器从原始信号中学习离散音频标记,有效地为音乐样本创建新的固定“词汇”。通过这种方法,他们可以在这些离散的音频标记上训练自回归语言模型,以生成新颖的标记、声音和音乐。随后使用 EnCodec 的解码器将这些令牌转换回音频空间,从而实现所需的音频生成。
AudioCraft 模型利用 EnCodec 神经音频编解码器从原始波形中学习离散音频标记。EnCodec 将音频信号映射到一个或多个并行的离散令牌流。然后使用单个自回归语言模型对来自 EnCodec 的音频标记进行递归建模。然后,这些生成的令牌被馈送到 EnCodec 解码器,将它们转换回音频空间并产生最终的输出波形。这种方法的灵活性允许各种调节模型来控制生成过程,例如利用预先训练的文本编码器进行文本到音频应用。
EnCodec 是一种有损神经编解码器,经过专门训练来压缩各种音频类型并以高保真度重建原始信号。其架构包含一个具有残差矢量量化瓶颈的自动编码器,生成具有固定词汇的并行音频标记流。这些不同的流从音频波形中捕获不同级别的信息,最终实现跨所有流的高保真音频重建。
2)文本转音频:AudioGen
AudioGen 深入研究了生成以描述性文本字幕为条件的音频样本的挑战性任务,扩展了该方法以涵盖有条件和无条件的音频延续。在生成复杂的音景(例如“有人在繁忙的街道上吹喇叭时狗叫”)的背景下,该模型面临着生成三种不同类别的声学内容的复杂挑战,其特征是不同的背景/前景元素、持续时间和声音。时间轴上的相对位置。这种组合极不可能出现在训练数据中,需要高水平的泛化、声音保真度、制作和母带处理能力。
AudioGen 提出了一种自回归文本引导音频生成模型,包括两个主要阶段。在初始阶段,原始音频通过神经音频压缩模型编码为离散的令牌序列,该模型专为端到端训练而设计,以从压缩表示中重建输入音频。为了增强音频生成的保真度,一组鉴别器在该过程中应用了感知损失。这种压缩技术不仅确保了高保真音频生成,而且保持了表示的紧凑性。
第二阶段采用自回归 Transformer-解码器语言模型,对从第一阶段获取的离散音频标记进行操作。此外,该语言模型以文本输入为条件。为了表示文本,使用了一个单独的文本编码器模型 T5,该模型在大量文本语料库上进行了预训练。这种预先训练的文本编码器极大地有助于推广当前文本音频数据集中缺少的文本概念。当处理多样性和描述性有限的文本注释时,这种功能变得尤其重要。通过结合这种多功能文本编码器,AudioGen 有效地解决了根据文本提示生成丰富多样的音频样本的挑战。
3)文本转音乐:MusicGen
MusicGen 是 AudioCraft 模型,致力于文本到音乐生成的挑战性任务,旨在根据文本描述生成音乐作品。该过程存在独特的困难,因为它涉及对长程序列进行建模。与语音不同,音乐需要利用整个频谱,从而导致音乐录音的采样率更高,通常为 44.1 kHz 或 48 kHz,而语音为 16 kHz。此外,音乐的复杂性源于多种乐器的和声和旋律的存在,从而形成了复杂的结构。
MusicGen 是一个简单且可控的音乐生成模型,Meta AI 提出了一个用于建模多个并行声学标记流的综合框架,比之前的研究提供了显着的进步。为了增强生成音乐的可控性,该模型结合了无监督的旋律调节,有助于制作符合给定和声和旋律结构的音乐。
MusicGen 采用基于自回归变压器的解码器,以文本或旋律表示为条件。该语言模型对从 EnCodec 音频分词器获得的量化单元进行操作,从而确保从低帧速率的离散表示进行高保真重建。此设置中的每个流都包含从各种学习的码本派生的离散令牌。为了解决这种复杂性,以前的方法提出了不同的建模策略。在这项工作中,Meta AI 引入了一种新颖且多功能的建模框架,可适应各种码本交错模式,探索几种不同的变体。通过利用这些模式,该模型可以利用量化音频标记的内部结构,从而增强音乐生成过程。
开源
遵循开源承诺,Meta AI 在https://github.com/facebookresearch/audiocraft提供了 AudioCraft 模型的代码。该版本还包括每个模型的训练代码和 API 文档。AudioCraft 是近年来最完整的生成音频版本之一,开源方法应该有助于加速生成人工智能这一新领域的研究。