
type
status
slug
summary
date
tags
category
password
Multi-select
Status
URL
勘误
标签
类型
icon
Publishe Date
贴文
🪄

OpenAI 停止使用用于识别 AI 书写文本的 AI 分类器
不久前,我从各种来源(包括LLM)获取了人类和人工智能生成的文本,并将其提交给 OpenAI 分类器。目的是衡量分类器检测文本内容来源的能力。
正如下面的摘录所示,在发布仅 5 个月后,在宣布分类器的文档中添加了一段文字。本文探讨了为什么这种类型的分类很困难,以及它最初是多么不准确。

LLM非常灵活,对请求的响应速度很快。可以要求LLM以这样的方式做出回应,即该回应看起来像是人类而不是机器编写的。
LLM还可能被要求以这样的方式写作,以欺骗人工智能检测器,使其相信它是人类写的,或者听起来像特定的个性或类型。
因此,该系统基于单词序列和选择。
任何严格的方法,例如通过散列和存储每个生成的输出部分以及生成的日期和位置,以某种方式对 LLM 输出加水印,然后让机构使用基于地理代码和时间窗口的最终文档进行查询,这是完全不可行的。还要考虑开源LLM的出现以及模型可以微调的程度。
当 OpenAI 宣布并推出一个经过训练来区分人工智能编写的文本和人类编写的文本的分类器时,提交的每个文档都被分为以下五个类别之一:
1️⃣不太可能由人工智能生成
2️⃣不太可能由人工智能生成
3️⃣不清楚是否是AI生成的
4️⃣可能是人工智能生成的
5️⃣可能是人工智能生成的。
这些类别本身是模糊且不明确的。
OpenAI基于微调的 GPT 模型训练了一个分类器来区分人类和人工智能编写的文本。该模型旨在预测文本的一部分是由人工智能生成的可能性有多大,并且来自各种来源,包括 ChatGPT。
下表是结果概述,左侧是文本来源,右侧是分类器准确性。结果的详细信息将在下面讨论......

OpenAI 明确指出:
我们的分类器并不完全可靠。在我们对英语文本“挑战集”的评估中,我们的分类器正确地将26% 的 AI 编写的文本(真实)识别为“可能是 AI 编写的”,而9% 的情况下,会将人类编写的文本错误地标记为人工智能编写的文本(误报)。我们的分类器的可靠性通常随着输入文本长度的增加而提高。与我们之前发布的分类器相比,这个新的分类器对于来自最新人工智能系统的文本更加可靠。
通过 Cohere LLM 生成的文本
我向Cohere LLM 提出了以下问题:
Write 2,000 characters of text on the importance of being punctual.下面,Cohere 生成的文本被复制到 OpenAI 的 AI 文本分类器中。
分类器的结果:可能是人工智能生成的。
因此,信心是正确的、充满信心的。
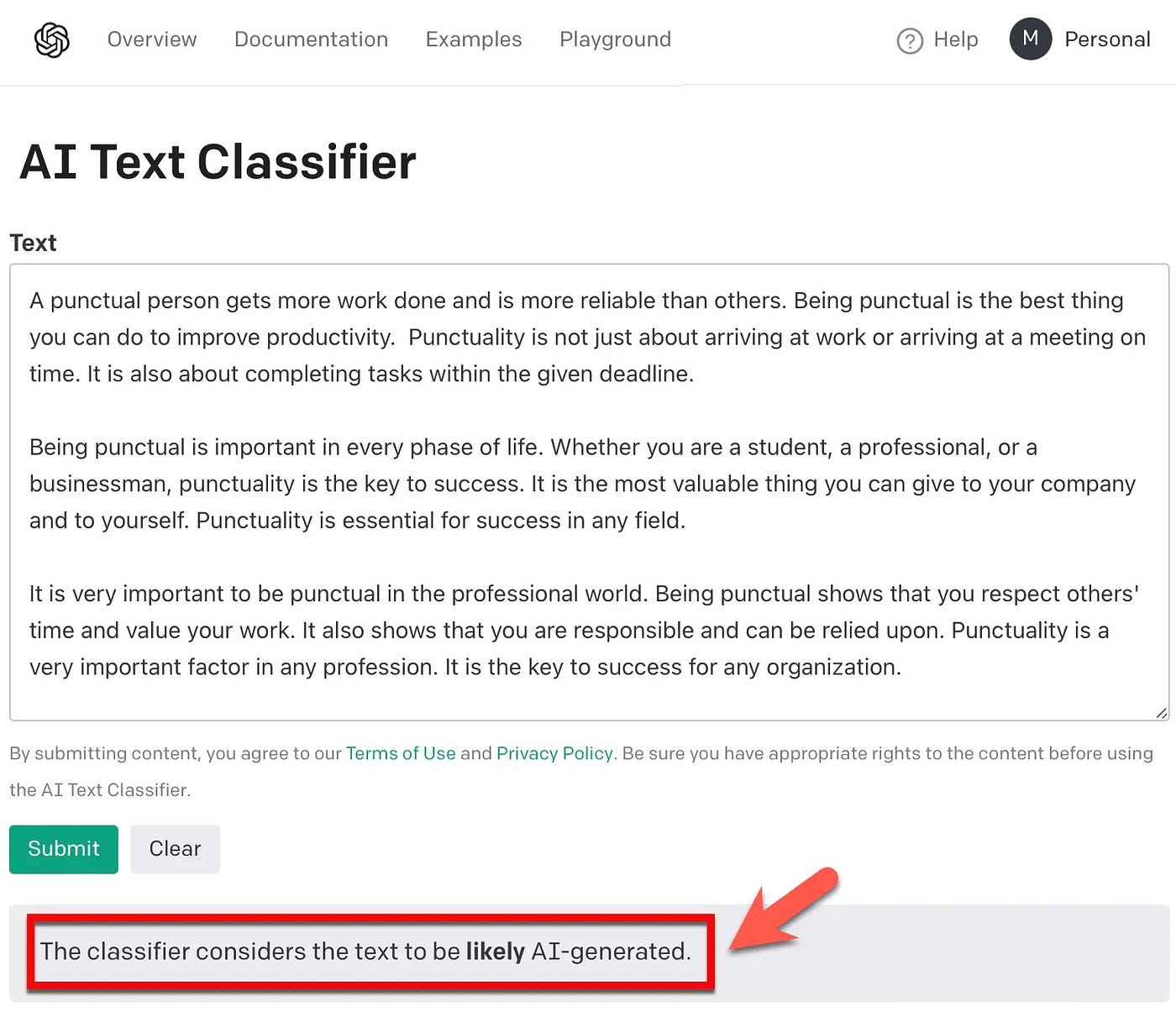
Cohere Playground中生成的文本在此提交给 OpenAI 的 AI 文本分类器。
通过 AI21Labs 生成的文本
在AI21Labs游乐场中发出了相同的生成命令……要求 AI21Labs LLM生成关于守时重要性的文本。
分类器的结果:可能是人工智能生成的。
因此充满信心地正确。
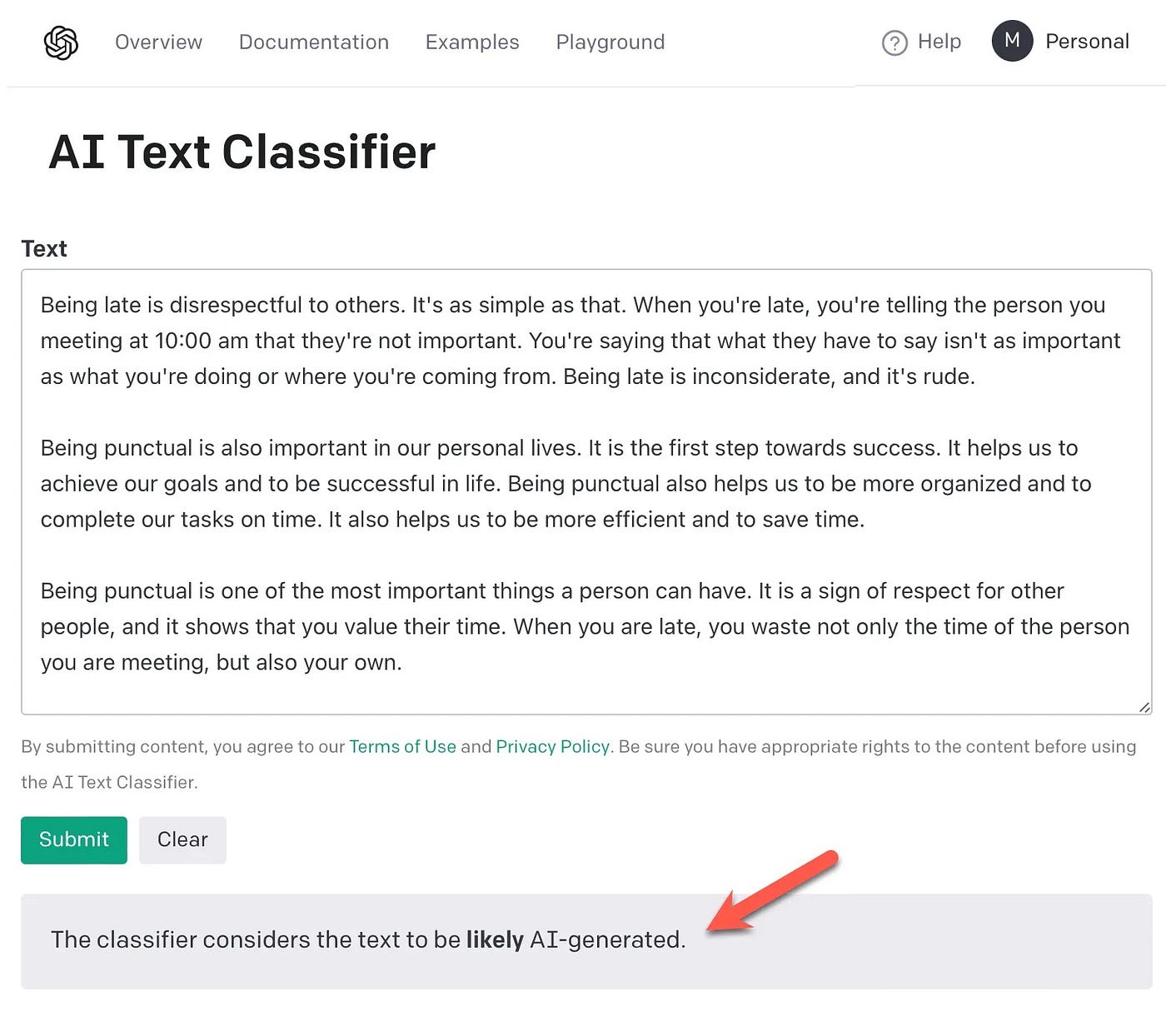
AI21Labs Playground中生成的文本在此提交给 OpenAI 的 AI 文本分类器。
ChatGPT
possibly下面您可以看到由 ChatGPT 生成的上下文……并由分类器进行评级。因此,与 Cohere 和 AI21Labs 相比,它更接近人类生成的文本。我本希望分类器能够满怀信心地陈述生成的人工智能。

OpenAI text-davinci-003 模型
text-davinci-003我还提交了一篇关于守时主题的500 字文本生成,并从 ChatGPT 收到了相同的答案;可能是人工智能生成的。我假设分类器能够清楚地检测
text-davinci-003ChatGPT 上生成的文本。来自网络的一篇文章
我从网上复制了一篇文章,分类器的结果在某种程度上是模糊的,但相当准确。

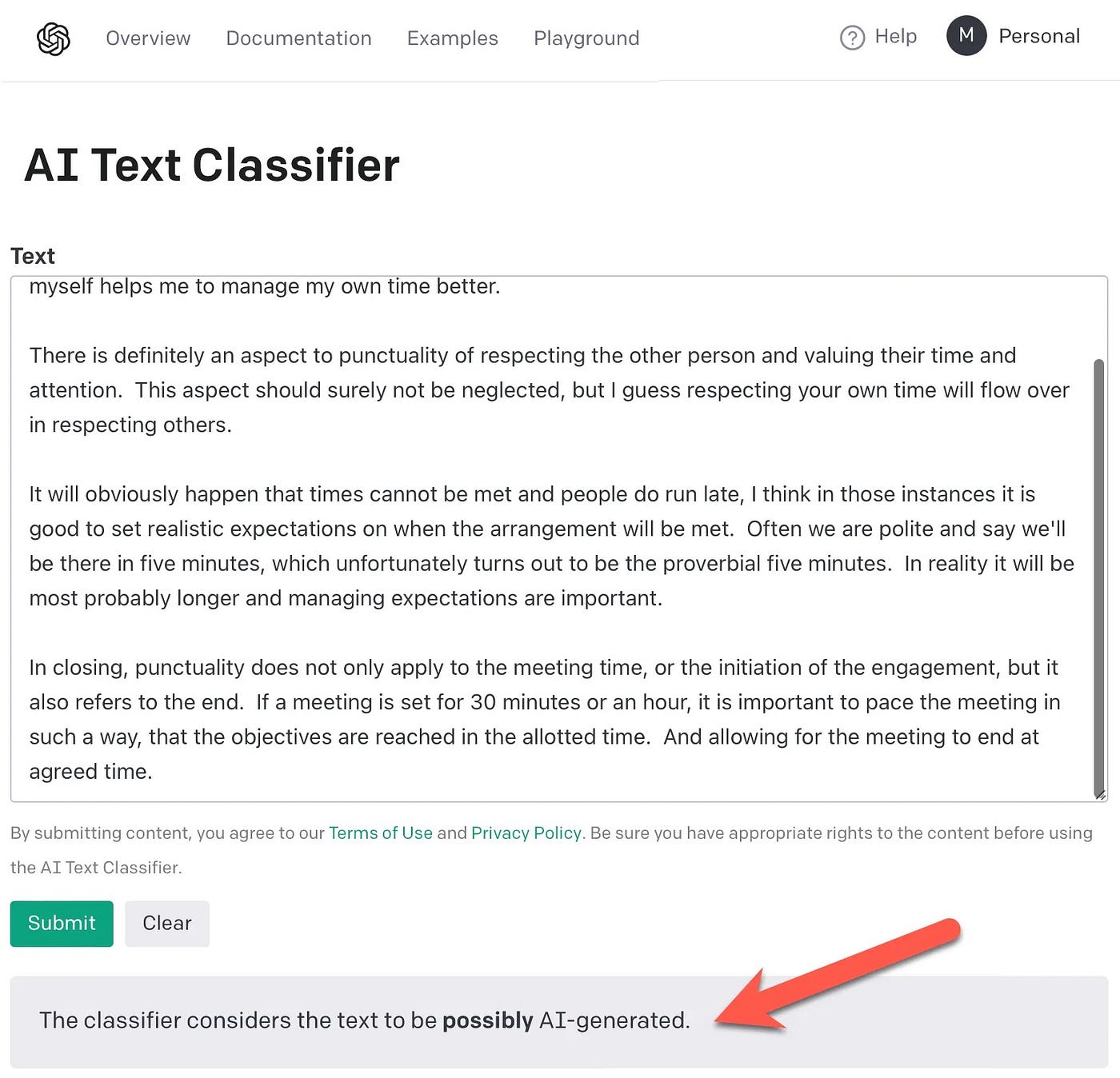
我自己的写作
以下是我就同一主题撰写的原创文章,OpenAI 将其标记为可能是人工智能生成的。如果是人工智能生成的,我预计结果会是“不清楚”。
但我赶紧补充一点,这篇文章很短,而且正如我之前所说,这篇文章含糊不清,没有太多明确的文字。
维基百科
考虑到人工智能文本分类器是在维基百科上训练的,我从维基百科上复制了一篇关于第一次世界大战的文章,并要求分类器审查内容。在这里我得到了正确的答案,也是最高的排名
very unlikely。ChatGPT 可以检测文本来源吗?
简短的回答是……是的。
结果是明确的,并且在我的几次尝试中,非常准确:

而且我自己写的回应也是正确的。

除了本文开头所述的准确性问题外,还有其他限制......
我用来作为写作前提的文本和主题非常通用和笼统。像这样更加模糊的内容很可能更难分类。
要分析的文本越长,结果就越可靠。人类书写的文本有时会被错误地标记为人工智能书写的文本。因此,似乎对“人工智能编写”的默认分类存在某种偏见。
分类器仅是英语的,不是多语言的。分类器对分类代码不可靠。人类编辑的人工智能生成的文本可以欺骗分类器。
数据
OpenAI 收集了人工智能生成和人类编写的文本的数据集。
人类书写的文本有三个来源:
- 维基百科数据集
- 2019 年收集的WebText 数据集
- 作为InstructGPT培训的一部分收集的一组人体演示
综上所述
显然,分类器的准确性从来都不可靠,OpenAI 公开声明了这一事实:“我们的分类器并不完全可靠”。
人们非常关注负责任的人工智能,我相信负责任的人工智能的一个方面始于LLM输入/输出的可观察性、可检查性和调整。
- 作者:Inevitable AI
- 链接:https://www.Inevitableai.ltd/article/share112
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。